 Electronica y Ciencia
Electronica y CienciaLos dominios de la entropía
Hace un montón que no publico un artículo, tanto que casi no me acuerdo de escribir, así que: Hola de nuevo.
Hoy vamos a hablar de uno de esos conceptos que levanta pasiones entre los aficionados a los palabros sin demasiada preocupación por su significado: la entropía. Si conoces este concepto y has visto documentales sobre universos paralelos y viajes en el tiempo lo siento mucho, este artículo no te va a gustar, porque va de estadística.
La entropía es un concepto físico muy fácil de comprender, lo que pasa es que alrededor de él se han escrito tantísimas cosas (con más o menos sentido artístico) que buena parte de lo que se dice es un misterio.
Estamos en 1850. Un tal Clausius, estudiando cosas que se calientan, estaba dándole vueltas a lo siguiente:
En un sólido, como puede ser una barra de hierro, los átomos están fijos. Cada uno ocupa su lugar dentro de la estructura cristalina y no se mueve. Pueden vibrar si calentamos el metal, pero siempre alrededor del punto que les corresponde. Entonces para decir dónde está cada átomo me basta con decir que es un metal y si acaso que tiene tal temperatura, con eso es suficiente.
En un líquido como el agua, es más complicado porque ya sí se mueven, fluyen. No tiene una estructura fija, pero las moléculas del agua, por mucho que se muevan, estarán dentro del agua. Así que su posición no puede ser cualquiera, tiene unos límites. Y lo mismo pasa con la velocidad. En un líquido las partículas rozan mucho entre sí y una no puede acelerar durante mucho tiempo sin darse con las demás. Así que más o menos tienen todas la misma velocidad.
Pero en un gas es distinto, muy distinto… por algo gas viene del griego Kaos. Las partículas de un gas pueden moverse libremente, ocupar la posición que quieran dentro del contenedor, moverse con cualquier velocidad, chocar unas con otras. Para describir el estado de un gas necesito decir la posición y velocidad de cada partícula que lo forma, porque no tiene ninguna estructura.
Así, un sistema es más complicado de describir físicamente cuantos más estados posibles tenga, y habrá más estados posibles cuanto menos estructurado (menos ordenado) esté. Y por tanto de su temperatura.
Voy a inventar una magnitud que indique lo difícil que es describir un sistema y la voy a llamar entropía.
Casi cien años después, en 1948, un ingeniero eléctrico graduado en matemáticas, poco conocido por entonces, pensó que este concepto de cuán difícil es describir un sistema no tiene por qué ser algo exclusivo de la física. Pensó que, en general, sea lo que sea que estemos describiendo necesitaremos más o menos información para hacerlo. Y publicó un articulito generalizando el concepto de entropía y dando una fórmula para calcular la cantidad de información.
Hay que decir que al principio no se dio cuenta, pero acababa de dar un salto de caballo en comunicaciones, comparable al que dio en 1822 el hijo de un sastre francés, cuando se empeñó en estudiar cómo se distribuye el calor en una placa. Y con el salto que daría junto a Harry Nyquist unos años más tarde. Las series de Fourier, la teoría de la información de Shannon y el teorema de Nyquist son los tres pilares sobre los que se sustenta toda nuestra era de las comunicaciones.
Supongamos que quiero una pizza:
por favor, una pizza de peperoni.
Ese mensaje tiene cierta cantidad de información, suficiente para que el camarero nos traiga una pizza de peperoni. Si ahora yo dijera:
una pizza con doble de peperoni
Estaría aportando información adicional al mensaje de antes. Pero aumentar la cantidad de peperoni no aumenta la cantidad de información, sólo cambia el mensaje, pero no lo hace más largo:
una pizza con triple de peperoni
una pizza con cuádruple de peperoni
Luego entonces la cantidad de información es la misma, aunque cambie el contenido de dicha información.
También podemos alargar el mensaje sin aportar información extra, pero entonces ciertas partes del mensaje serán redundantes. Algo así como haría Jimmy el Dos Veces:
una pizza margarita
una pizza margarita, horneada, con su albahaca y su tomate
La redundancia no tiene por qué ser mala. Nos permite seguir entendiendo el mensaje aunque una porción se pierda. Muy importante en el lenguaje hablado, por ejemplo.
La entropía, y esta fue la gran aportación de Shannon, está íntimamente ligada a la compresión de los mensajes. Porque un mensaje lo podremos comprimir hasta la cantidad mínima de información que lleva. Aquí influye, como en la entropía física, la cantidad de estados posibles y la estructura interna (el orden), por ejemplo el mensaje:
ccc
puede describirse como “3 ces”, y sin embargo:
cccccccccccccccccccccccccc
puede escribirse como “26 ces” mucho más comprimido. De igual modo
abcdefghijklmnopqrstuvwxyz
puede describirse como “las letras ordenadas de la a a la z”, y podría abreviarse sencillamente como
a-z
mientras que:
kdupwopylacnghzrcgojdjxuwv
aún teniendo la misma longitud que antes y las mismas letras, no puede ser abreviado. Luego de alguna manera esta última cadena tiene más entropía, más desorden, o más aleatoriedad que las anteriores. ¿Correcto? Bueno… ya veremos.
Para un sistema informático, encontrar la estructura interna de un mensaje, y así la forma más eficiente de transmitirlo, es un problema muy difícil hoy en día sólo resuelto en parte. Por lo que hay que buscar otro modo de calcular la entropía, uno que se base sólo en el contenido, puramente estadístico.
Estamos de acuerdo en que si un mensaje está formado por una sola letra repetida, tiene tantas posibilidades (estados posibles) como veces repitamos la misma letra. Si un mensaje tiene dos posibles letras, tendrá más estados y más cuanto más largo sea, etc. Luego la entropía de un mensaje será mayor cuanto más largo, más símbolos distintos aparezcan y más raros sean.
El concepto anterior es muy general. Y viene a decir que las cosas más frecuentes aportan menos información que las cosas raras. Por ejemplo las palabras “el, un, que, a, de” se repiten muchísimo en un texto y si falta una no pasa nada, pero la palabra “entropía” es infrecuente. Tanto que si eliges una palabra para clasificar este artículo seguramente sea esa: “entropía”, porque es precisamente la que diferencia este de otros artículos sobre otros temas. Las palabras “que” o “un” están en casi todos los artículos en español, hablen de lo que hablen, por lo que nos van a aportar muy poca información.
Palabras aleatorias
Del concepto anterior se suelen deducir cosas erróneas. Por ejemplo que cadenas como:
fseptrnhgjzoywmkxqilcubadv,
qjhrbvozwykiscgnpfaemtdulx,
prsfcaidhtubwyxjvozeqmkgln o
eynawotsbqpvgcikuzxhdmjlrf
tienen “más entropía” que, por ejemplo,
abcdefghijklmnopqrstuvwxyz o
zyxwvutsrqponmlkjihgfedcba
sin embargo esto sólo es así porque nosotros hemos decidido una ordenación arbitraria del abecedario. Ese contexto, esa estructura interna a un ordenador se le escapa, es ajeno a la definición de entropía. Estos mensajes tienen todos la misma entropía: la equivalente a un mensaje de 26 letras todas distintas entre sí.
Luego la entropía así descrita no es una medida de aleatoriedad en la disposición de las letras sino de aleatoriedad en cuanto al contenido de letras distintas y la frecuencia de estas.
Si hablamos de palabras, nuestras palabras no son así. Nuestras palabras no están compuestas por todas las letras del abecedario dispuestas en distinto orden. Las letras en nuestras palabras se repiten, son unas más frecuentes que otras, forman sílabas, etc. Así que sí, se puede calcular la entropía de una palabra, pero no estará ligada al orden, sino a si las letras que contiene son más o menos probables en el conjunto. La cuestión es elegir bien el conjunto, porque las letras no tienen la misma prevalencia en inglés, que en español, que en polaco.
Dominios aleatorios
Hay virus informáticos, troyanos, que se comunican remotamente con su panel de control por medio de llamar a determinados dominios, que muchas veces generan con un algoritmo pseudoaleatorio. Así el dominio cambia cada día, o cada hora. Algunos pueden generar miles de dominios aleatorios para un mismo día con el objetivo de despistar a los investigadores de malware, porque sin tenerlos todos no hay forma a priori de saber cuál es el verdadero. Y pueden ser miles.
La cuestión es si los dominios aleatorios tendrán más entropía que los dominios habituales. Si eso es así podríamos detectar fácilmente quién se está conectando a este tipo de dominios aleatorios, y sabremos que su equipo tiene un malware.
Aquí aplicamos la entropía en cada dominio por sí mismo. O sea, que no nos importa si el usuario se conecta a más o menos dominios. Esa otra técnica se usa sobre todo para detectar el envío de spam: normalmente uno manda correos a los mismos dominios muchas veces cada día (poca entropía), si un usuario manda correos a muchos dominios pocas veces (mucha entropía) querrá decir que hay algo raro.
Pero vamos a seguir el primer método: asignar a cada dominio una medida de entropía.
Necesitaremos una muestra de dominios legítimos, para obtener la frecuencia relativa de cada letra, también necesitaremos una muestra de dominios habituales así como una muestra de dominios aleatorios para compararlos y ver si nuestro test puede diferenciar los habituales de los aleatorios.
La muestra de dominios legítimos la obtendremos, por ejemplo, del TOP 1.000.000 de Alexa, que podemos descargar de aquí: http://s3.amazonaws.com/alexa-static/top-1m.csv.zip. Tened en cuenta que el resultado estará muy ligado a fuente que elijamos. Partimos de la base de que esa lista es confiable y sólo contiene dominios y bastante conocidos. En un primer vistazo confirmamos que así es.
La muestra de dominios buenos (control negativo) será el TOP 500 de dominios con más conexiones desde España, también de Alexa. La muestra de dominios aleatorios (control positivo) la bajaremos de pastebin haciendo una búsqueda por Downadup domains.
Lo primero es crear una base de datos de frecuencias relativas para cada letra a partir de la fuente. Hay que tener la precaución de asignar un valor para los símbolos que no estén en nuestra fuente, es decir, imaginemos que una letra es tan poco corriente que ningún dominio la contiene. No va a darse el caso ahora, pero sí más adelante. Para esos símbolos asignaremos el valor más bajo posible: media ocurrencia. En otras palabras asumimos que no sale porque la fuente es corta, si la lista de palabras fuera el doble de grande asumimos que saldría al menos una vez. Es una presunción arbitraria, por supuesto.
Tenemos un par de programitas en Perl para hacer los cálculos. Hay un enlace al final del artículo.
Alimentamos el programita feed.pl con el TOP de Alexa y el resultado es un fichero con datos estadísticos de frecuencias relativas para cada letra:
"_" : 3.860414
"0" : 0.001153
...
"9" : 0.000435
"a" : 0.086051
"b" : 0.022417
"c" : 0.045581
"d" : 0.031477
"e" : 0.102742
"f" : 0.017150
Como es de esperar, las letras “e” y “a” son las más comunes y tienen frecuencias relativas más altas que las demás. Mientras que los números ocurren menos veces en los nombre de los dominios.
Ha habido que tener la precaución de eliminar el Dominio de Primer Nivel porque al ser mucho “.com” o “.org” introducían en sesgo importante. También he eliminado los caracteres que no son alfanuméricos, como el guión o el punto.
Ahora tenemos un segundo programa, que calcula la entropía de cada palabra de una lista, siguiendo la fórmula dada por Shannon. El razonamiento lo podéis ver en la Wikipedia, pero dicho de una forma rápida se trata de calcular el logaritmo de la rareza de algo (o sea la inversa de la frecuencia) y multiplicar por cuántas veces aparece. Así con todos los símbolos y finalmente se suma. El resultado es la cantidad de información necesaria para representar la muestra.
Un paso adicional que también haremos es dividir por la longitud total del dominio, calculando la entropía por símbolo. Porque si no lo hiciéramos así favoreceríamos los dominios más cortos frente a los más largos.
Como decíamos antes, esta forma de cálculo no tiene para nada en cuenta el orden de las letras. Si lo aplicamos sobre las cadenas de antes el resultado es el mismo para todas. Por la sencilla razón de que todas tienen las mismas letras el mismo número de veces:
3.702 abcdefghijklmnopqrstuvwxyz
3.702 zyxwvutsrqponmlkjihgfedcba
3.702 fseptrnhgjzoywmkxqilcubadv
3.702 qjhrbvozwykiscgnpfaemtdulx
3.702 prsfcaidhtubwyxjvozeqmkgln
3.702 eynawotsbqpvgcikuzxhdmjlrf
Vamos a probar qué entropía nos da para los 500 dominios más visitados en España, que era nuestro control negativo. Es decir, esperamos entropías en general bajas.
2.518 series
2.537 terra
2.592 elitetorrent
2.617 sensacine
2.622 elcorreo
...
4.363 los40
4.593 office365
4.862 7769domain
4.939 ad131m
5.222 bet365
Muy bien, parece que funciona. Va desde 2.5 para los dominios con letras más usuales, hasta más de 5 para los que tienen nombres con muchos números. Vamos a comparar los resultados con varios dominios aleatorios del troyano Downadup que sólo están formados por letras y esperamos que los valores sean mucho más altos.
2.730 ecrreaictepimeli
2.787 rrirdtecowehieer
2.906 lpciilaowoaiiwea
2.920 reitweamiicfaife
2.940 rrrglcrderidihga
...
4.371 wpcwphjjljpqwffj
4.383 jjjocwpgwqrczqpf
4.413 jfhjefpjjjjfjgtp
4.460 wdhhwpwwqqqzjpmo
4.467 jjziwwwtwzwhfjpj
4.557 pzdjqwpgjjfcjfjc
Vaya… los dominios aleatorios arrojan resultados desde el 2.7 para los que están formados por letras muy frecuentes hasta el 4.5 para los que tienen muchas letras infrecuentes.
Pues desde el punto de vista entrópico, la frecuencia de los caracteres en los dominios aleatorios no se diferencia mucho de los dominios legítimos. Si bien la decepción es menos profunda cuando representamos el resultado en un histograma:
(todas las imágenes las podéis ampliar haciendo clic)
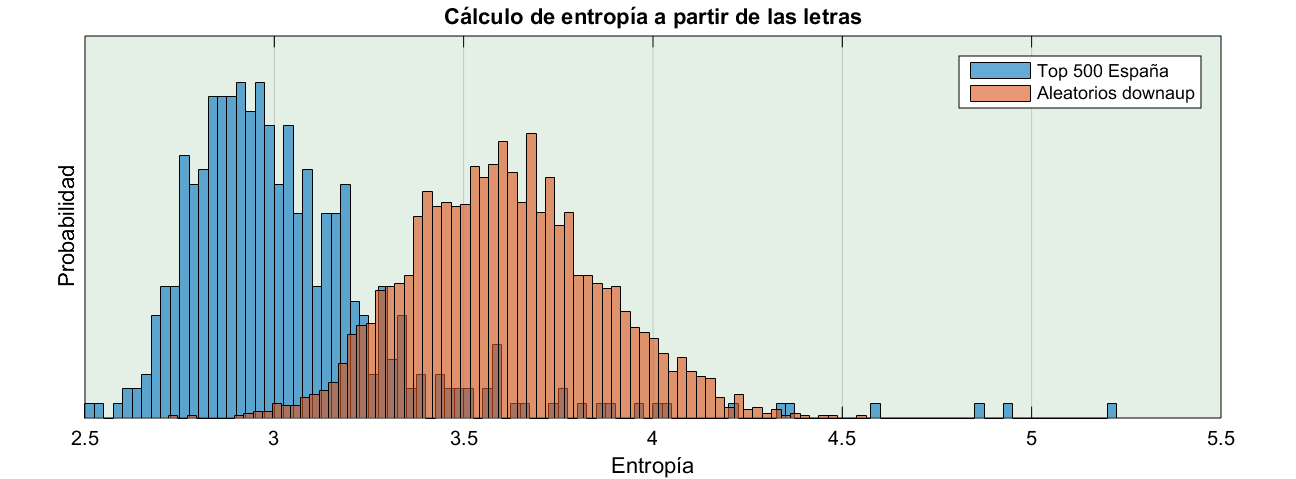
La decisión
No, no es una novela de John Grisham. Es que histograma en mano, tenemos que contestar a la pregunta: ¿el dominio X es aleatorio o no?
Señor abogado, a la vista del histograma anterior podríamos decir tres cosas:
- La entropía media de los dominios legítimos está en torno al 2.9.
- La entropía media de los dominios aleatorios está en torno a 3.6.
- Las dos distribuciones se solapan en parte.
Y es en esta tercera cuestión donde se desarrolla toda una teoría estadística sobre los test de hipótesis de la que tenemos aquí, entre manos, un caso práctico.
Decir si un dominio es aleatorio o no en base a su entropía no es más que fijar un corte. Decir por ejemplo, que todo dominio cuya entropía supere 3.25 lo damos por aleatorio. El límite de 3.25 es arbitrario, lo he dicho por decir. Por tú uno distinto si quieres.
Precisamente porque las distribuciones no están separadas, fijemos el umbral que fijemos siempre vamos a encontrar algunos dominios que:
- Tengan un nombre raro aun siendo legítimos, como “bet365” por ejemplo. Lo daríamos como aleatorio.
- Sean aleatorios, pero dé la casualidad de que usan letras muy frecuentes, y lo demos como legítimo.
Para la pregunta ¿El dominio X es aleatorio? el primer caso supone un falso positivo; mientras que el segundo caso es un falso negativo.
Si ponemos el límite en 2.6 detectaríamos como aleatorios todos los dominios de Downadup. Nuestro test sería muy sensible. Claro que también detectaríamos como aleatorios buena parte de los que no lo son. Nuestro test sería muy sensible sí, pero poco específico.
En el otro lado, si ponemos el límite en 4 sólo detectaríamos como aleatorios algunos legítimos que son casos extremos, todos los que diéramos como aleatorios lo serían de verdad. Nuestro test sería muy específico. Claro que también nos dejaríamos sin detectar muchos de los de Downadup. Nuestro test sería muy específico sí, pero poco sensible.
Reflexiona lo anterior con esta frase, y cuando te marees sigue leyendo:
La sensibilidad es la fracción de verdaderos positivos y la especificidad la fracción de verdaderos negativos. -Wikipedia
¿Entonces el límite donde lo ponemos? Pues en algún punto donde encontremos un equilibrio entre los verdaderos positivos y los falsos positivos.
Por ejemplo, ¿qué tal si representamos en un gráfico la relación entre positivos y falsos positivos? Cuando esta relación sea máxima, maximizaremos los positivos minimizando los errores. Suena bien.
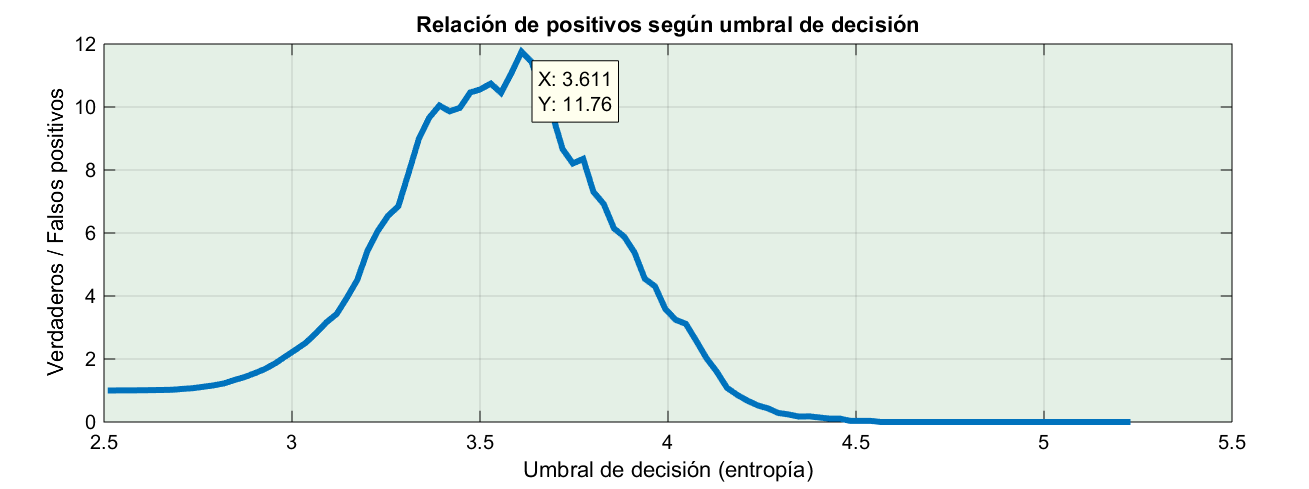
El punto óptimo según este criterio está en entropía 3.6, punto en que cometeríamos un fallo por cada 12 aciertos. Oye, es un 90% de eficacia; la leche.
Sólo hay un problemilla… que si bien la cantidad de falsos positivos con este umbral es poca (un 4%), los dominios aleatorios detectados no llegan ni a la mitad de los que deberían ser, tan sólo pillamos el 48%.
Lo siento, pero la realidad es cruel. Las pruebas 100% sensibles e infalibles no existen.
En otros tipos de test, como las pruebas clínicas, el criterio hay que pensarlo con más detenimiento. Por ejemplo en una prueba de alergias para un pre-operatorio siempre se prefiere detectar una alergia por leve que sea, aunque a veces salga alguna que otra duda. Se requiere una prueba muy sensible. En el lado contrario, antes de meter a un paciente al quirófano más vale asegurarse de que tiene lo que pensamos. Aquí los falsos positivos son un problema muy serio, en tales casos queremos pruebas muy específicas. Ni que decir tiene que a la hora de la verdad no se decide todo por un test, influyen otros factores como los antecedentes, la historia clínica o, si no la tenemos, la prevalencia de la enfermedad, etc.
Así que lo mejor es que representemos en un gráfico la fracción de falsos positivos que estamos dispuestos a aceptar, y la fracción de positivos reales que conseguiríamos con ello:
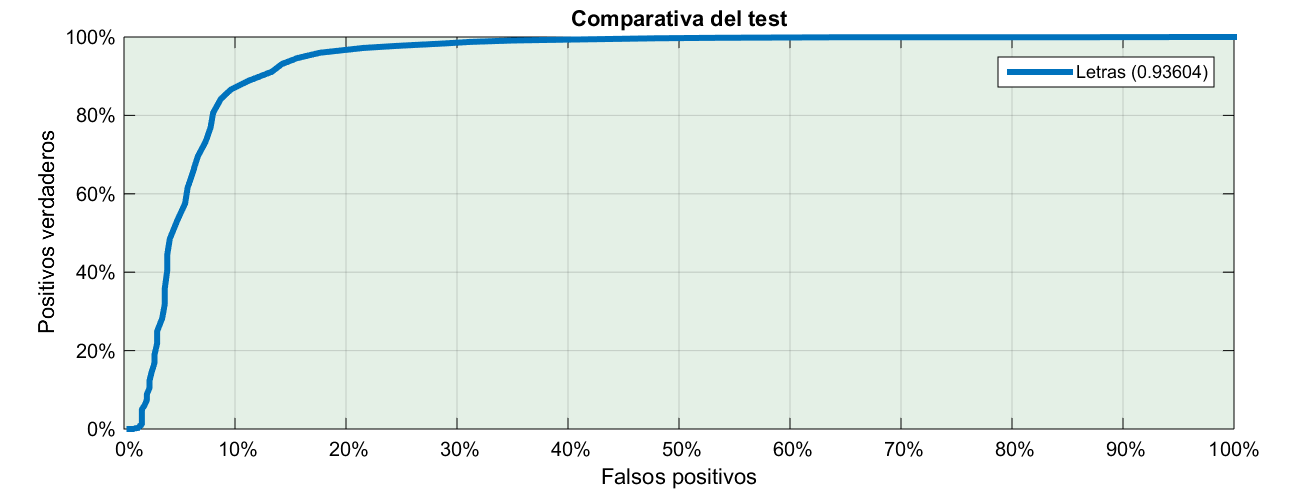
{kind=link}
</a>
Habitualmente se escoge un umbral tal que detecte el 80% de positivos y luego, junto con el test, indicamos la probabilidad de que sea un falso positivo. Dado el gráfico anterior ya nos hacemos una idea de lo bueno o lo malo que es el test según la curva se acerque más a la esquina superior izquierda: eso significaría el 100% de positivos detectados con 0 errores.
Dígrafos
Una de las quejas que teníamos en el apartado anterior era que en el cálculo de la entropía no representaba ningún papel la ordenación de las letras. Vamos a intentar mejorar eso haciendo el cálculo con parejas de letras. Aunque la palabra dígrafo sólo se refiere a parejas de letras que tienen un sonido único como “ch” o “rr”, yo la voy a usar aquí para indicar parejas de letras.
¿Cual es el propósito de esta variación? pues mejorar el test aprovechando que la pareja de letras “ch” es más frecuente que la pareja “hc”. Ahora nuestros elementos ya no van a ser letras, sino dígrafos. Por ejemplo, separando google en dígrafos estaría compuesto por:
^g
go
oo
og
gl
le
e$
Los símbolos “^” y “$” indican el comienzo y el final de la palabra. Los voy a incorporar para que también entre en el juego la probabilidad de que un dominio empiece por una letra o acabe por otra.
Bueno pues, de nuevo alimentamos la base de datos. Lo que ocurre es que donde antes sólo había 26 letras y 10 números, ahora hay 1368 combinaciones. Ahora veis que tiene sentido el comodín “_” para los símbolos sin ninguna aparición.
Ordenando el TOP500 de España como antes obtenemos este resultado:
5.402 pinterest
5.474 meristation
5.491 eldiariomontanes
5.548 mileroticos
5.598 pelismaseries
...
8.925 fiuxy
8.955 los40
9.266 bet365
9.307 7769domain
9.588 1and1
9.900 ad131m
A primera vista es bastante similar al resultado que salía antes con las letras solas. A ver con los aleatorios:
6.056 ecrreaictepimeli
6.133 rrirdtecowehieer
6.305 dcleweelowheergg
6.531 reitweamiicfaife
6.539 potpegigegecpptr
...
9.799 wmjzjgzlmwmoqwgp
9.837 wdhhwpwwqqqzjpmo
9.927 rzcjlpfzfjjwpjwi
9.956 jmhzpcpjjhlwqfza
10.191 pzdjqwpgjjfcjfjc
Los dos primeros que salen son igual que en el caso anterior. El tercero ya es diferente y se nota que contiene dígrafos comunes en inglés cómo “wh”, “ee”, “we”, etc. Además cómo el número de combinaciones ahora es mayor, el valor numérico de la entropía también es superior.
La prueba de fuego, vamos a representar la curva de positivos vs. falsos positivos y comparar:
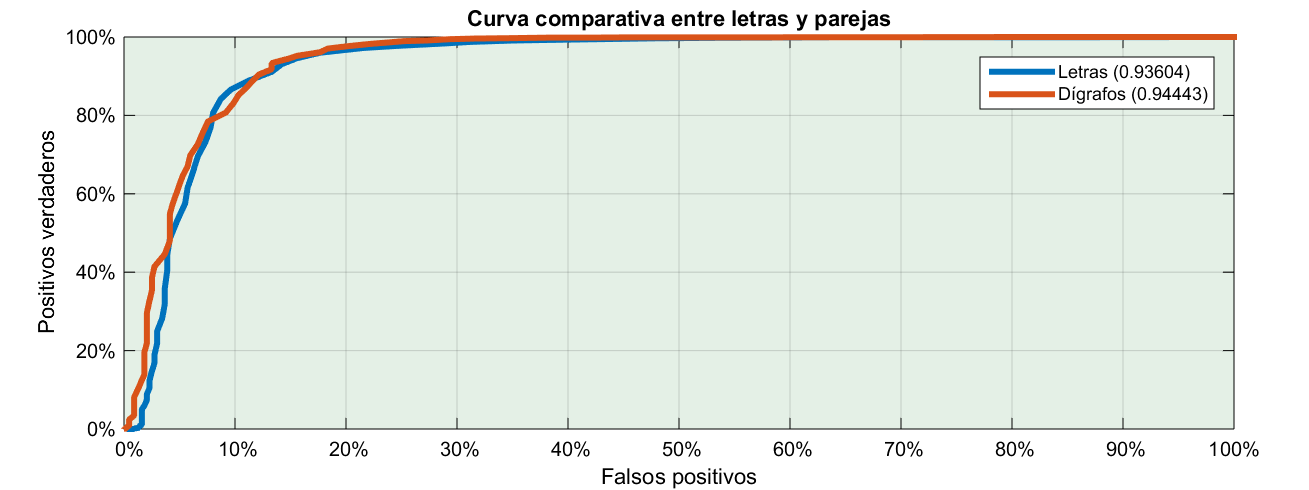
A simple vista no se diferencian mucho. Sin embargo hay un criterio objetivo para indicar si un test es mejor que otro. Se supone que mientras más arriba a la izquierda esté la curva, mejor diferenciación hace el test. Pues el criterio consiste en calcular el área bajo la curva que es el número que tenéis en la leyenda.
No os lo he dicho pero resulta que en realidad esa curva que habíamos puesto desde el primer caso es muy famosa. Tan famosa que hasta tiene nombre: se llama curva ROC. Algunos dicen que lo de ROC viene de Curva del Operador de Radar. Otros dicen que viene de Característica Operativa del Receptor.
Y es que, según cuenta la leyenda, tras el ataque a Pearl Harbor los americanos se pusieron las pilas para intentar diferenciar los aviones enemigos través de la señal de radar. Lo que pasa es que los radares de aquella época no estaban muy evolucionados. De hecho se habían inventado unos años antes cuando alguien pensó en freír a los pilotos enemigos con un “Rayo de la Muerte”. Lo malo es que vieron que necesitaban una cantidad enorme de energía para eso. Esos experimentos junto a la observación casual de que los aviones causaban interferencias en los receptores de alta frecuencia llevaron a la invención del radar.
Al grano, el área bajo la curva en el primer caso, cuando calculábamos la entropía sólo a base de letras sale 0.936, de un máximo de 1. En el segundo caso, utilizando dígrafos sale 0.944. La diferencia es tan poca que objetivamente no valdría la pena el esfuerzo porque el resultado es prácticamente el mismo.
Trígrafos
La siguiente prueba es con tríos de letras a ver si así el resultado es mejor. Por ejemplo “google” esta vez estaría compuesto por:
^go
goo
oog
ogl
gle
le$
Es de suponer que la probabilidad de que dos letras habituales salgan juntan en algo generado al azar es baja. Pero tres letras juntas es todavía más difícil. De hecho, hay 49248 combinaciones posibles, incluyendo los símbolos de comienzo y final de palabra.
Haremos lo mismo que antes: tomaremos el TOP 1M de Alexa, calcularemos la probabilidad de ocurrencia de cada trío en todos los dominios, y luego utilizaremos esa probabilidad para calcular la entropía del TOP 500 en España y de los de Downadup.
Para el caso de los dominios legítimos, tenemos este resultado:
5.290 sport
5.332 blogspot
5.736 marca
5.779 series
...
9.529 3djuegos
9.820 fiuxy
10.064 ad131m
10.151 adplxmd
10.409 7769domain
Hasta ahora muy parecido a lo anterior. Y para los aleatorios:
8.272 dcleweelowheergg
8.369 ecrreaictepimeli
8.674 otelprchhhefeigr
...
13.613 pfpfzwpqjrgfhhqa
13.682 pzdjqwpgjjfcjfjc
13.865 rzcjlpfzfjjwpjwi
No queda del todo claro que sea mejor. Vamos a compararlo dibujando la curva ROC junto a los otros dos.
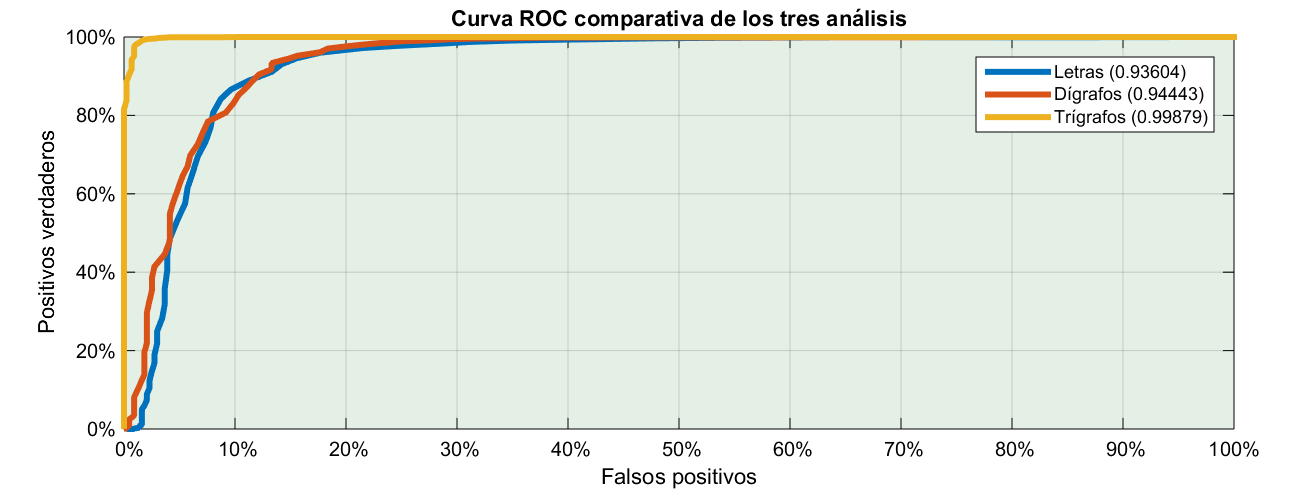
¡Hala! los otros dos daban buenos resultados, pero es que este es casi infalible. Veamos cómo son las distribuciones de ambos para encontrar el por qué del resultado.
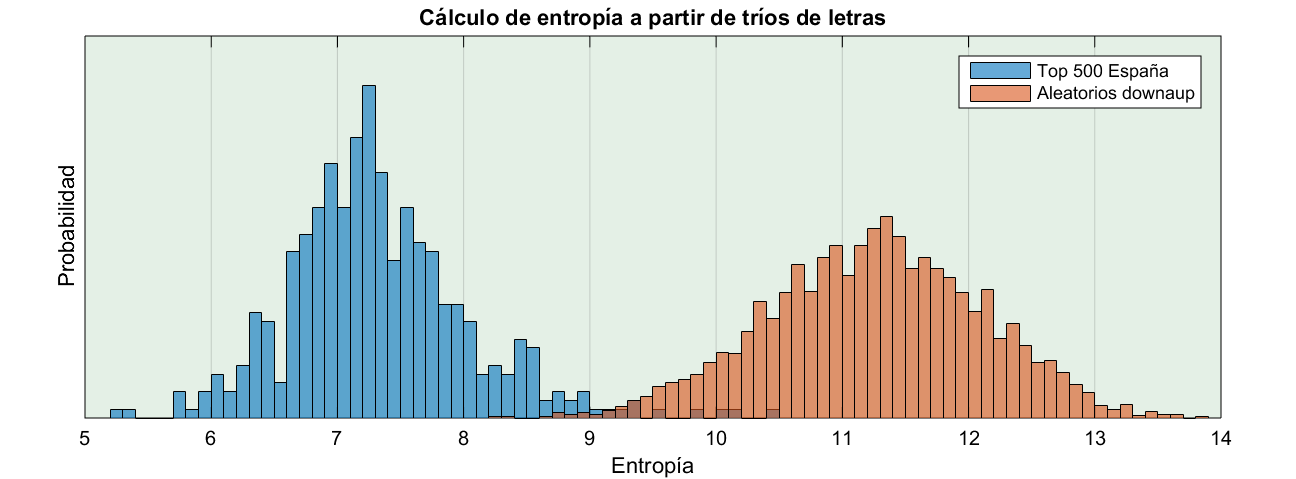
Principio GIGO
Me gustaría terminar este artículo hablándoos del principio GIGO. Desde el comienzo todo lo que hemos hecho ha sido alimentar una base de datos de probabilidades y obtener resultados en base a la entrada de partida. Pero ¿en algún momento hemos comprobado si el TOP 1M de Alexa es de fiar?
Vamos a hacer una cosa, calculemos la entropía utilizando el método de trígrafos de lo que llamamos “dominios válidos” y ordenémoslo de menor a mayor entropía. A ver qué sale. Los primeros dominios que aparecen, los de menor entropía son:
5.011 blogs
5.148 mares
5.151 rester
5.175 store
5.182 caree
5.185 lines
5.195 inter
5.213 comed
5.214 stern
5.216 tions
Dominios cortos sin mayor interés. Claro que, si nos vamos a mirar los dominios “válidos” con mayor entropía:
14.252 0p78qfr8q7
14.259 r0j57fbs5wvd74b
14.259 xn22c9ba4a8bwcb4i4a5cg8b
14.297 061x79xzldqja621
14.310 9cd47096ab1495d8d3b18667f6a52b9c
14.383 b33d8ac9ea7318e83d193ec9cf4
14.391 g5p7wt0zbk
14.422 b5cf5a1ec553b9d09df8ebf30885601c1c
14.430 491gxrw8ifhy8hg1
14.495 bff9ddc870e3ab3c1a2a8f6158328af2df
14.653 5e9e45c3f9381f5ffa8c5a5bd97405e99fb
¡Oh, atrevida ignorancia! Resulta que entre nuestra lista de dominios válidos se han colado algunos que más bien parecen de los malos. Aparecen dominios como 491gxrw8ifhy8hg1.com o 5e9e45c3f9381f5ffa8c5a5bd97405e99fb.com que casualmente parece un hash y que, al contrario de lo que cabría imaginar, existe y resuelve a la ip 50.19.87.86.
Así es imposible distinguir nada. Son estos últimos dominios los que alteran la probabilidad y hacen que el test de dígrafos no salga como uno esperaría.
Por favor, nunca olvides esto: todos los sistemas que trabajan con unos datos de entrada para generar una salida se rigen por el principio GIGO: Garbage In Garbage Out. Y esto se aplica desde los ordenadores hasta los médicos o los pilotos de aviones. Viene a decir que siempre que tengas que basarte en unos datos de entrada para tomar una decisión, los selecciones y los limpies todo lo posible, o de lo contrario los resultados que obtengas no servirán para nada.
Angler Exploit Kit
Pero ¿y si el dominio no es del todo aleatorio? Angler EK es un kit de exploiting del que se está oyendo últimamente. Podéis ver una descripción aquí: Threat Spotlight: Angler Lurking in the Domain Shadows. Para ocultar sus llamadas hace uso de una técnica que se llama Domain Shadow y que consiste en robarle las credenciales a un administrador de algún dominio de GoDaddy y crear subdominios del dominio principal apuntando a la IP del panel de control.
Por ejemplo, alguien obtuvo las credenciales del dominio keytone.net y dio de alta algunos subdominios
036ncy4zgj.keytone.net
042emb3ilv.keytone.net
06yd2l4vc9.keytone.net
Para el administrador del dominio es totalmente transparente y no advertirá nada a menos que liste los subdominios que tiene a su nombre, ya que por lo general son gratuitos. Para el analista de malware es una faena porque muchas veces las listas blancas se hacen por dominio completo, por lo que si keytone.net está en lista blanca, todos sus subdominios -incluyendo los anteriores- también lo estarán.
Este es un gráfico comparativo de la entropía de los dominios de Angler EK, con respecto al Top 500 de España, calculada con tríos de letras.
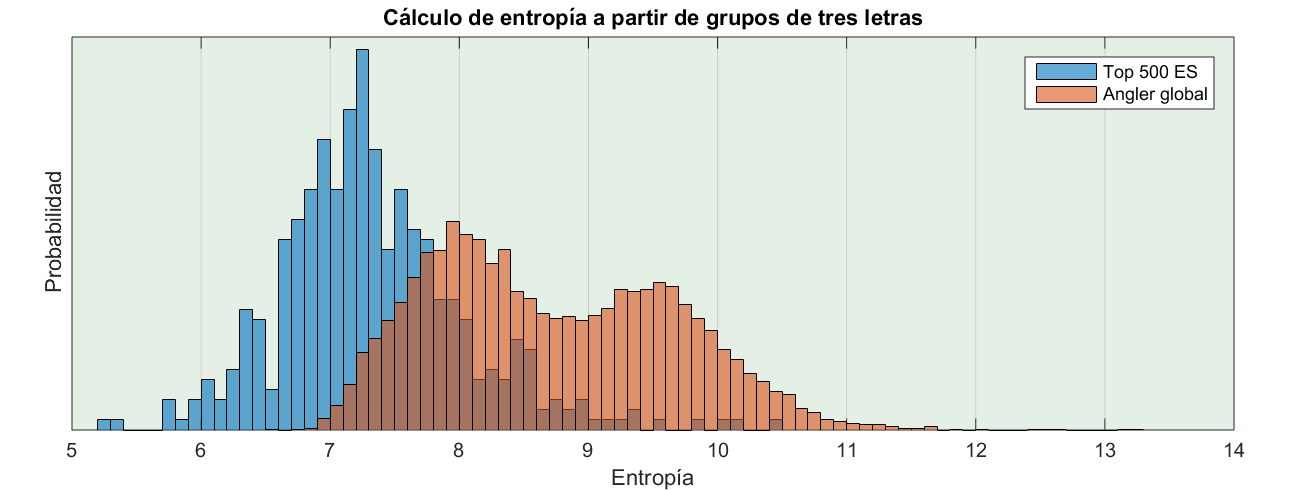
¿Por qué la distribución de Angler tiene dos máximos? Obviamente porque hay dos tipos de dominios diferente. Si miramos el listado veremos que los subdominios pueden ser pseudoaleatorios,como estos:
acaibehbjdjd.mysupercouponzz.info
acaibehbjjcjb.mysupercouponzz.info
acaibehdbjifi.mysupercouponzz.info
acaibehdcabid.mysupercouponzz.info
acaibehdefgcc.mysupercouponzz.info
acaibehdgghhh.mysupercouponzz.info
acaibehgcgfgh.mysupercouponzz.info
o bien formados por palabras, como estos otros:
ounces.rhinestonetemptations.com
clashes.rhinestonetemptations.com
country.rhinestonetemptations.com
getting.rhinestonetemptations.com
spacing.rhinestonetemptations.com
regulate.rhinestonetemptations.com
collecting.rhinestonetemptations.com
employment.rhinestonetemptations.com
possession.rhinestonetemptations.com
Ahora parece razonable ver las dos distribuciones mezcladas. El máximo de mayor entropía corresponde a los dominios aleatorios, mientras que el de menor entropía corresponde a los que usan palabras. Hay que recordar que lo que estamos calculando es la entropía por trío, no por carácter, no por dominio completo. Lo que implica que si el dominio tiene una parte aleatoria, pero esta es corta en comparación al nombre completo, la entropía saldrá baja.
Según Cisco, si leéis el enlace anterior, Angler ha variado su forma de generar dominios. Cabe preguntarse si se notará en la distribución. Así que comparemos la entropía de los dominios recientes con el listado global:
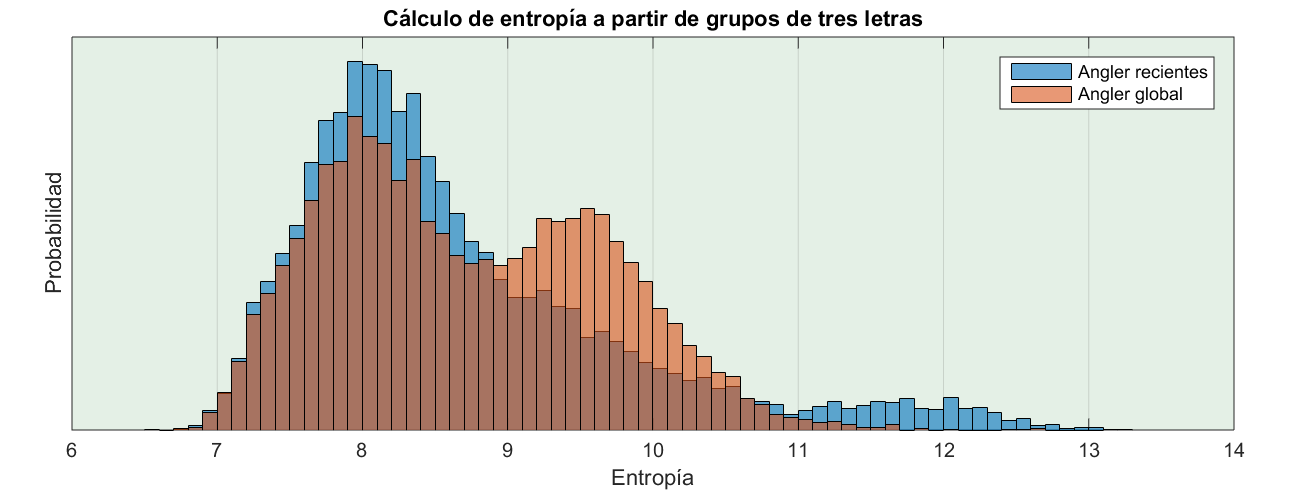
Fijaos que en el grupo de dominios recientes (en azul) el máximo de la derecha ha desaparecido. Bueno, no ha desaparecido del todo sino que ahora está muy a la derecha pero es mucho menor (en torno al 12). Eso quiere decir que los creadores de Angler, con muy buen criterio, han decidido favorecer los dominios formados pos palabras.
Es de suponer que estos serán más difíciles de diferenciar, como se ve perfectamente en el gráfico siguiente. Comparamos la distribución de los dominios de Angler con el Top 500 de España. Y, tal como puede verse, las distribuciones están bastante próximas.
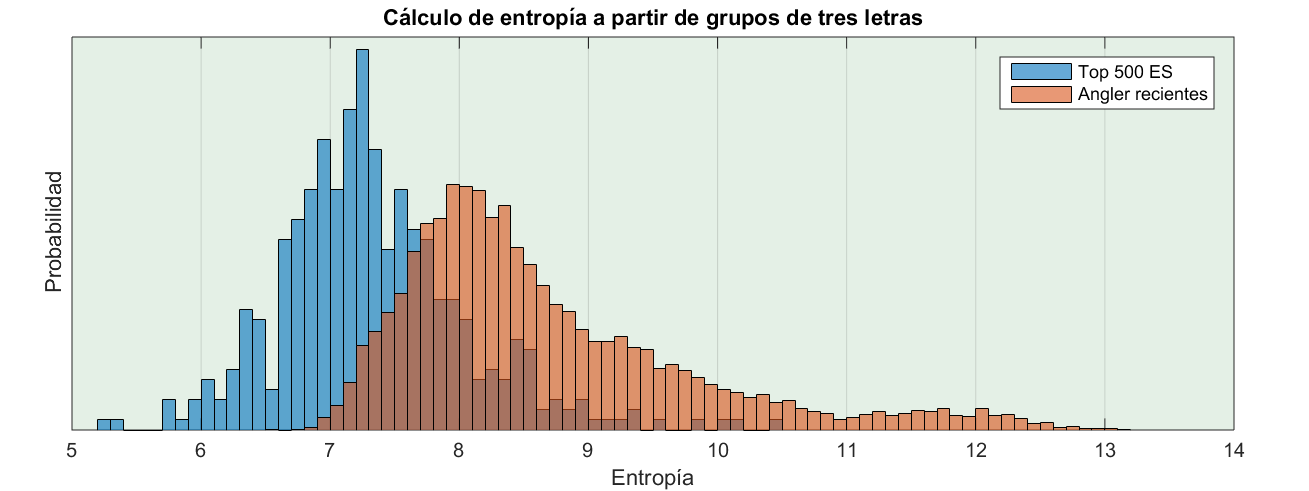
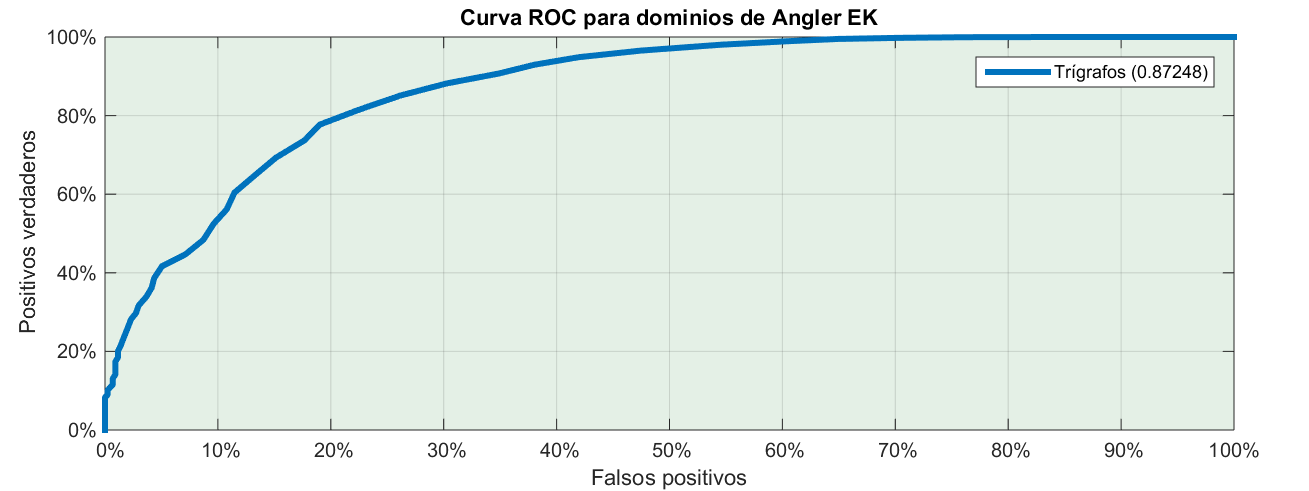
La última pregunta, si el test serviría para diferenciarlos la podéis responder vosotros viendo la curva ROC y sabiendo que el área bajo la curva es 0.87.
Nada más por el momento. Gracias por leer hasta aquí. Los scripts en Perl, ficheros, resultados, etc los podéis encontrar en este enlace: fuentes.