 Electronica y Ciencia
Electronica y CienciaMemorias Flash: almacenamiento en IoT
- La tecnología Flash
- Protocolo SPI: JEDEC Id
- Leer, escribir y borrar con SPI
- El device-tree
- Nuestro propio dtoverlay
- MTD - Memory Technology Device
- JFFS2 y wear leveling
- Conclusión
- Enlaces para profundizar
En este recorrido sobre las memorias Flash te llevaré de la electrónica aplicada a la informática más abstracta. De las señales digitales, a la estructura de datos de un sistema de ficheros, pasando por el árbol de dispositivos (device-tree) de los sistemas Linux embebidos.
Aunque llamemos memorias Flash a los pendrives, SSD o tarjetas eMMC, no es de lo que vamos a hablar hoy. Aunque sí, les llamamos Flash porque internamente llevan una memoria Flash. Normalmente NAND Flash. Sin embargo, ninguno de estos dispositivos expone la memoria directamente.

Un pendrive solo con el chip de interfaz, para que le pongas la Flash que tú quieras. Aliexpress.
Los pendrives llevan un chip que actúa como Flash Translation Layer. Por un lado habla el mismo protocolo USB que hablaría un disco duro y por el otro se comunica con el chip NAND.
De lo que vamos a hablar es de las memorias tal como se usan en los sistemas embebidos.
En la siguiente foto puedes ver una arquitectura típica. Los cuatro chips son:
- Microprocesador o SoC. En el centro.
- Memoria RAM. A la izquierda. Fíjate en los meandros de las pistas. Son para que todas midan lo mismo (eléctricamente hablando). Cuando se trabaja con relojes muy rápidos es importantísimo que todos los bits lleguen a la vez.
- Almacenamiento Flash NAND. A la derecha, arriba. Se utiliza para guardar el firmware, la configuración y el sistema de ficheros.
- Almacenamiento Flash NOR. A la derecha, abajo (8 patillas). Tiene mucha menos capacidad que la NAND. En esta placa se utiliza para guardar dos versiones del cargador de arranque (bootloader); una actualizable por el usuario y la otra, de rescate, fija.

Detalle de la placa RB711 de Mikrotik. mikrotik.com
No siempre están presentes ambos tipos de Flash, generalmente se usa una o la otra.
La tecnología Flash
Las Flash son un tipo especial de EEPROM. Se caracterizan por tener mayor capacidad. Las hay de dos clases: NAND y NOR.
Las NAND tienen muchísima capacidad, son rápidas para leer y muy rápidas para escribir. Es el tipo de memoria que llevan por dentro los pendrives y los discos duros de estado sólido (SSD). Son un poco más difíciles de usar que las NOR.
Las NOR no tienen tanta capacidad, son muy rápidas al leer pero muy lentas de escribir. Por eso se usan para guardar cosas que pueden cambiar, aunque no frecuentemente: Como firmware, BIOS o configuraciones de usuario.

Comparación entre memorias Flash de tipo NAND y NOR. researchgate.net
Para alcanzar capacidades mayores es preciso empaquetar las celdas ocupando el menor espacio posible de la oblea (aumentar su densidad). Lo cual exige dos sacrificios:
- Celdas más pequeñas. Tienen una capa de óxido más delgada, que se va deteriorando poco a poco con el uso.
- Cableado interno más simple. Significa que en una Flash no podemos hacer cosas que sí podemos con otras EEPROM.

Parecen dientes, pero dentro de una Flash hay millones de transistores como este. theses.fr
De ahí las tres reglas básicas que debes conocer para trabajar con Flash:
- No puedes modificar una celda: puedes escribirla, pero para cambiar el valor primero tienes que borrarla.
- No puedes borrar sólo una celda: tienes que borrar bloques enteros.
- Cada ciclo de escritura/borrado degrada lentamente las celdas: el número de veces que puedes hacerlo es limitado.
A ver, limitado, del orden de cien mil ciclos. Puede parecer mucho pero para según qué cosas es muy poco.
Piensa en un disco duro, por ejemplo. La mayoría de ficheros apenas cambian. Pero otras partes cambian todo el tiempo: logs que se escriben continuamente, ficheros que cambian de tamaño, la fecha de último acceso…
Al cambiar siempre los datos de una misma zona, esas celdas se agotarán rápidamente. En días o semanas.
Cuando alguna celda falle, ese bloque ya no se puede utilizar. Quedarán menos bloques disponibles, lo que a su vez implica un mayor desgaste de los restantes. Aumentando la probabilidad de que otro falle. Este proceso realimentado lleva a la muerte prematura del chip.
La solución es evitar que unos bloques se utilicen por encima del resto. Eso es lo que se conoce por wear leveling (nivelar el desgaste).
Protocolo SPI: JEDEC Id
Vamos a usar una W25Q64 (datasheet), de la marca Winbond (eso es importante, ya lo veremos). Con 64 Mbit (o sea 8 MBytes).

También hay memorias Flash en encapsulado DIP. EyC.
Este tipo de Flash funcionan con protocolo SPI.
El bus SPI se parece al I2C en que ambos son protocolos serie síncronos y usan una topología master/slave (ver el bus I2C a bajo nivel.
Pero hay dos diferencias importantes entre ellos:
- El SPI no usa direcciones. En SPI cada esclavo tiene una línea llamada chip select. Y sólo atiende al bus cuando este cable está a nivel bajo. Así que en vez de usar direcciones, el master baja la línea CS del chip a quien va dirigido el comando. Es más simple pero requiere un cable extra por cada esclavo. Tampoco hay señales de inicio, parada, ack, ni nada de eso.
- El SPI es full duplex es decir, el controlador y el esclavo pueden hablarse el uno al otro simultáneamente. Por eso no hablaremos de leer o escribir en el bus, sino de intercambiar o transferir datos.
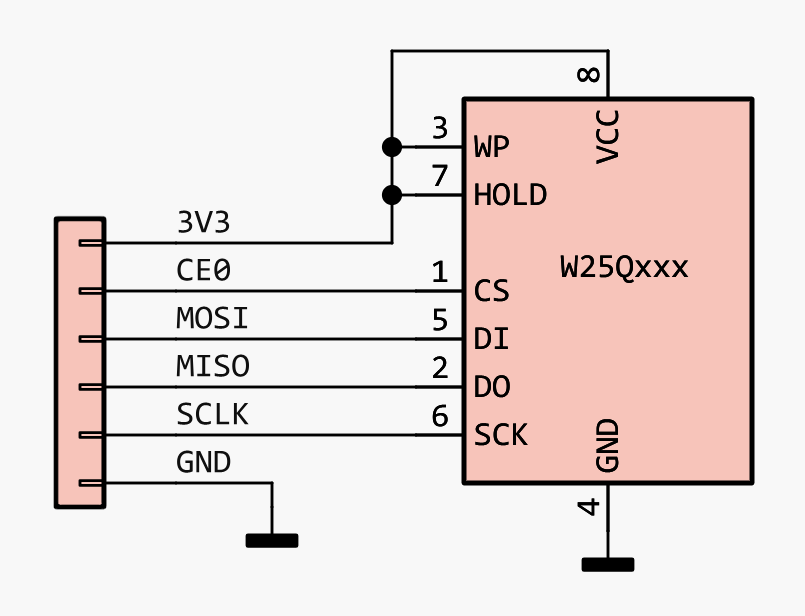
Esquema básico de conexión. EyC.
Además de alimentación y masa, el protocolo SPI utiliza 4 cables:
- CS (Chip Select): Cada chip en el bus tiene su propia línea de chip select. Todas están a nivel alto. La bajamos para indicar a un determinado slave que la siguiente transmisión va para él.
- MOSI (Master Out Slave In): Aquí sólo escribe el master y lee el slave.
- MISO (Master In Slave Out): Aquí sólo escribe el slave y lee el master.
- SCLK (Serial Clock): El reloj. Las datos se pueden fijar en el flanco de subida o bajada del reloj. Según el modo.
Conectaremos la memoria a una Raspberry Pi 3. Tenemos un puerto SPI en el conector GPIO con dos líneas de chip select:

En estas patillas hemos conectado la Flash de arriba. pinout.xyz
Ahora debemos activar el puerto SPI añadiendo lo siguiente en /boot/config.txt (según tu versión, /boot/ puede llamarse de otra manera):
dtparam=spi=on
Tras reiniciar comprobamos que existen dos dispositivos spidev, uno para cada línea de chip select (aunque se puede ampliar, sigue leyendo):
pi@raspberrypi:~$ ls -l /dev/spi*
crw-rw---- 1 root spi 153, 0 Jan 1 1970 /dev/spidev0.0
crw-rw---- 1 root spi 153, 1 Jan 1 1970 /dev/spidev0.1
Para saber si responde, vamos a probar a mandarle un comando que se llama JEDEC ID y tiene el código 9F.

Diagrama de secuencia del comando Read ID. Datasheet de ZB25VQ80ATIG
Debemos transferir 4 bytes.
- Hacia el chip enviaremos
9F xx xx xx; losxxda igual, pueden ser ceros. - Y del chip recibiremos
00 ID1 ID2 ID3. Siendo el primer byte recibido (ID1)EFpropio del fabricante.
Lo haremos en python:
import spidev
# Open SPI
spi = spidev.SpiDev()
spi.open(bus = 0, device = 0)
# Set SPI speed and mode
spi.max_speed_hz = 500000
spi.mode = 0
data = [0x9F, 0x00, 0x00, 0x00]
print("Sent: " + " ".join("{:02x}".format(n) for n in data))
spi.xfer(data)
print("Recv: " + " ".join("{:02x}".format(n) for n in data))
Observa como xfer reemplaza los datos de entrada en data por los datos recibidos.
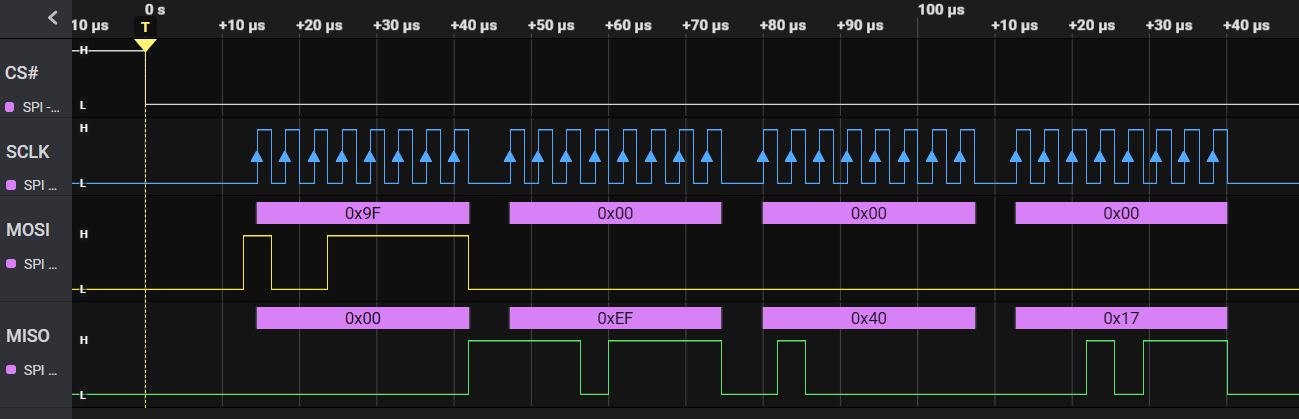
Para leer el identificador intercambiamos 4 bytes. EyC.
Obtenemos este resultado:
$ python jedec.py
Sent: 9f 00 00 00
Recv: 00 ef 40 17
El JEDEC ID es 0xef4017. Este dato va a ser importante cuando hablemos del dtoverlay.
Leer, escribir y borrar con SPI
El comando 03 sirve para leer datos. Debemos enviar 03 y a continuación 3 bytes más para indicar en qué posición de la memoria queremos empezar a leer.
Veamos qué hay en la dirección 11 22 33 y siguientes:
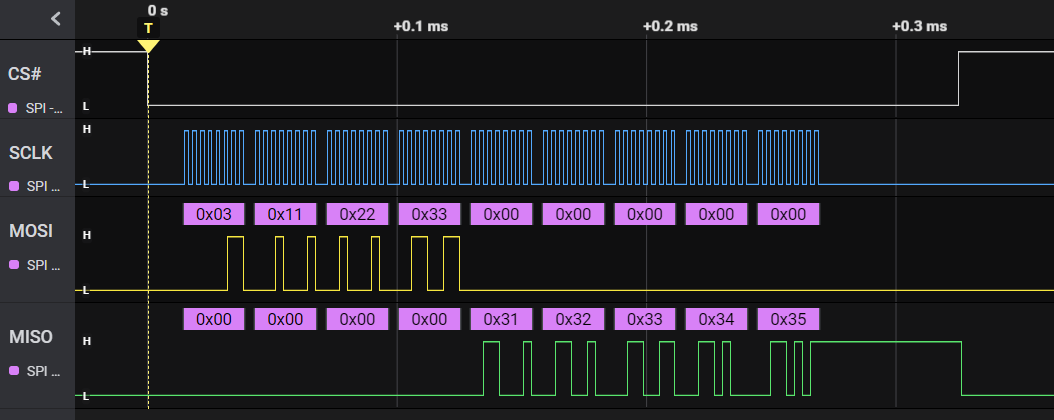
Leemos de la posición 0x112233. EyC.
$ python read.py
Sent: 03 11 22 33 00 00 00 00 00
Recv: 00 00 00 00 31 32 33 34 35
El comando 02 se llama page program y lo usamos para escribir. Funciona enviando 02, luego 3 bytes como antes, con la posición donde queremos escribir, y a continuación los bytes a escribir.
No obstante, estos chips están protegidos contra escritura accidental.
Antes de escribir o borrar cualquier cosa hay que enviar el comando Write Enable (06). Este comando pone a 1 el bit Write Enable Latch (WEL). Tras la operación de escritura, volverá a 0 automáticamente.
Vamos a escribir el valor AA en las mismas posiciones de memoria de donde leímos antes. No esperamos que el chip devuelva nada en esta operación, por eso los datos recibidos son todos 00:
$ python write.py
Sent: 06
Recv: 00
Sent: 02 11 22 aa aa aa aa aa aa
Recv: 00 00 00 00 00 00 00 00 00
Comprobamos lo que hemos escrito, esperamos que sea AA:
$ python read.py
Sent: 03 11 22 33 00 00 00 00 00
Recv: 00 00 00 00 20 22 22 20 20
Pues no. Como te decía al principio, puedes escribir una celda (hacer que valga 0). Pero no puedes hacer que vuelva a 1. Para eso tendrías que borrarla.
Y no se pueden borrar sólo unas cuantas celdas, hay que borrar el bloque entero. Que pueden ser desde 4k hasta 128k según la memoria.
El device-tree
Cuando usamos la Flash para guardar firmware (en un ESP32, por ejemplo), el micro habla con ella así directamente en SPI. Pero si guardamos configuración, será más práctico hacerlo en forma de ficheros.
Particiones de una Flash en un router doméstico. EyC.
Basta poner lo siguiente en el fichero config.txt para conseguir que la reconozca el kernel; así nos aparecerá como un dispositivo más del sistema:
dtoverlay=jedec-spi-nor,flash-spi0-0
¿Pero qué hace ese comando?
Déjame hablarte del device-tree. Todos los sistemas necesitan conocer su árbol de dispositivos. Para saber no sólo qué es lo que tiene conectado sino “como se usa”: la línea IRQ, direccionamiento de memoria, etc. Quizá aún recuerdes la época en la Microsoft anunciaba a bombo y platillo su sistema Plug and Play.
Los PCs están pensados para ser modulares y soportar hardware de todo tipo. Cuentan con buses complejos que soportan enumeración de hardware.
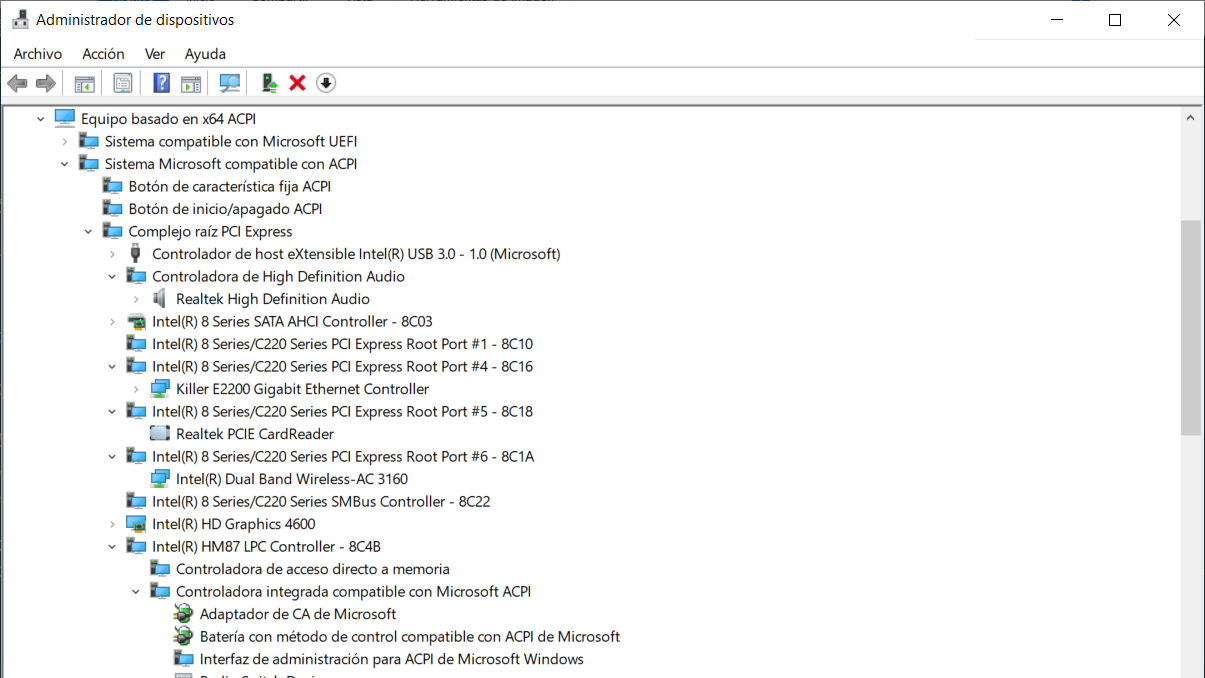
Árbol de dispositivos ACPI en Windows. EyC.
Te pego un párrafo del manual del comando lshw (en Linux) donde lista los mecanismos de enumeración más habituales:
It [lshw] currently supports DMI (x86 and IA-64 only), OpenFirmware device tree (PowerPC only), PCI/AGP, CPUID (x86), IDE/ATA/ATAPI, PCMCIA (only tested on x86), SCSI and USB.
En un dispositivo embebido sus buses son más sencillos y no soportan enumeración. Por un lado, porque la memoria y CPU son recursos escasos y se prima la eficiencia por encima de todo. Pero principalmente porque el hardware no suele cambiar (es el que viene de fábrica en la placa y listo).
Si los datos referentes al hardware estuvieran fijos en el kernel, habría que compilarlo para cada SoC específico. Peor aún, habría que recompilarlo cada vez que quisieras añadir hardware nuevo o, simplemente, activar o desactivar el que viene.
Por eso se inventó el device-tree: una estructura de datos en memoria que le dice al kernel qué periféricos tiene y dónde están. Mucho más flexible.
La estructura completa se expone en /proc/device-tree. Es binaria, pero se puede pasar a texto plano con el comando dtc.
$ dtc -I fs -O dts /proc/device-tree
Aunque siempre es más legible ir a la fuente original.
En una Raspberry Pi 3B como la mía, el fichero principal es bcm2710-rpi-3-b.dts.
Este incluye el fichero bcm283x.dtsi que configura el SPI:
spi: spi@7e204000 {
compatible = "brcm,bcm2835-spi";
reg = <0x7e204000 0x200>;
interrupts = <2 22>;
clocks = <&clocks BCM2835_CLOCK_VPU>;
#address-cells = <1>;
#size-cells = <0>;
status = "disabled";
};
Fíjate en tres cosas:
-
La linea
compatiblees donde se le dice al kernel qué estamos configurando. En este caso un devicetree/bindings/spi/. -
Con línea
regle decimos al driver SPI la posición de memoria donde nuestro SoC tiene mapeados los registros:0x7E204000. Tal como se indica en el datasheet: BCM2835 ARM Peripherals. -
La línea
statusestá en disabled. Es decir, por defecto el SPI estaría deshabilitado.
Pero también se incluye el fichero bcm270x-rpi.dtsi, que dice:
__overrides__ {
spi = <&spi0>,"status";
Eso significa: «el valor del parámetro spi lo usas como valor de status en spi0».
¡Por eso tuvimos que poner antes dtparam=spi=on! Da igual que pusieras 1 / true / yes / on, en cualquier caso se va a traducir por okay (activo).
Si con dtparam podemos modificar parámetros, con dtoverlay podemos insertar nodos completos en la estructura.
El device-tree es una herramienta muy potente. En la Raspberry te sirve, entre otras cosas para:
- hacer que reconozca nuevo hardware (un RTC, un ADC, o una memoria Flash)
- asignar funciones a los pines (tal como un interruptor de apagado por software)
- hasta puedes añadir líneas de chip select para tener más de dos dispositivos SPI.
Nuestro propio dtoverlay
La línea dtoverlay=jedec-spi-nor,flash-spi0-0 hace que durante el arranque se cargue el fichero /boot/overlays/jedec-spi-nor.dtbo.
Se puede decompilar con dtc o irte directamente al código fuente: jedec-spi-nor.dts
Sin embargo, como tiene varios parámetros y es difícil de seguir, vamos a escribir nosotros uno más simple: eyc-spi-nor.dts.
Este fichero se divide en dos fragmentos, y tiene una triple misión:
-
Un primer fragmento destinado a desactivar
spidev0. Puesto que esa línea va a estar usándola el driver de SPI-NOR, estespidevdará error. Así que ponemos su estado adisabled:fragment@0 { target = <&spidev0>; __overlay__ { status = "disabled"; }; }; -
Y un segundo fragmento, que por un lado activa
spi0(poniendostatusaokay) y por otro lado inserta el subnodo jedec,spi-nor:fragment@1 { target = <&spi0>; __overlay__ { status = "okay"; spi_nor@0 { compatible = "jedec,spi-nor"; reg = < 0x00 >; spi-max-frequency = < 1000000 >; }; }; }; };
Ahí, en el subnodo jedec,spi-nor, es donde podemos decirle qué chip select queremos usar (línea reg), la velocidad (spi-max-frequency) e incluso forzar un modelo de Flash compatible si no funciona el JEDEC ID.
Porque el kernel, al detectar el nodo jedec,spi-nor llamará al driver /drivers/mtd/spi-nor. Y este lo primero que hace es lanzar por SPI el comando 9F. ¿Recuerdas? El JEDEC ID.
De hecho, el driver spi-nor tiene un catálogo de IDs:
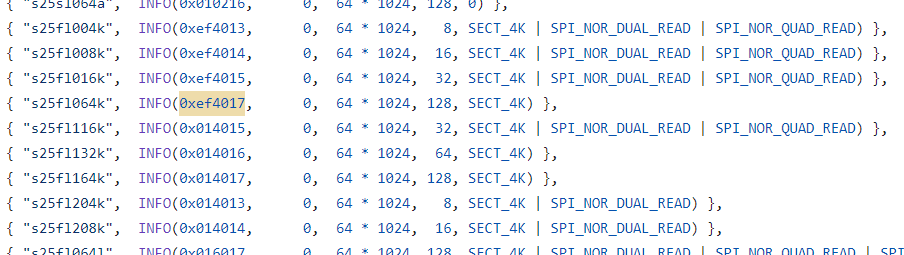
La s25fl064k de Spansion tiene el mismo ID que la w25q64 de Winbond. spi-nor/spansion.c
Puede ocurrir que la tuya no la reconozca, y entonces te dirá:
spi-nor spi0.0: unrecognized JEDEC id bytes: 5e 60 14
A mí me ha pasado con la primera Flash que probé. Una ZB25VQ80 reutilizada de una placa ESP-01S (la misma placa de Proyectos a batería y cerveza fría).

Memoria ZB25VQ80 reutilizada de un ESP-01. No la reconocía. EyC.
Una vez escrito el overlay, lo compilamos y lo guardamos junto al resto:
# dtc -I dts -O dtb -o /boot/overlays/eyc-spi-nor.dtbo eyc-spi-nor.dts
No hace falta reiniciar para cargarlo:
# dtoverlay eyc-spi-nor
Si todo ha ido bien nos debe decir algo así:
spi-nor spi0.0: s25fl064k (8192 Kbytes)
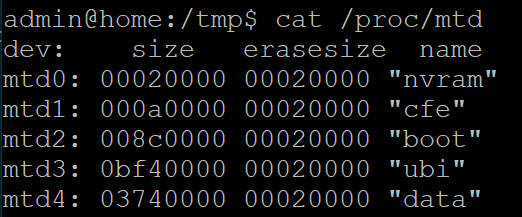
Y tendremos en /proc/mtd una Flash con 8 Mbytes que se puede borrar por sectores de 4 kbytes:
pi@raspberrypi:~$ cat /proc/mtd
dev: size erasesize name
mtd0: 00800000 00001000 "spi0.0"
MTD - Memory Technology Device
Los dispositivos de almacenamiento clásicos, como discos duros, memorias USB, eMMC, etc. son dispositivos de bloques.
La clave está en que:
- los bloques son pequeños, de 512 bytes por ejemplo.
- un bloque sobrescribe al anterior sin necesidad de borrarlo antes.
En las Flash los bloques son grandes (de 4 kbytes como mínimo) y no se pueden sobrescribir.
Por eso el kernel reconoce las Flash, no como un dispositivo de bloques, sino como otro tipo peculiar de dispositivo, que se llama MTD (Memory Technology Device).
$ ls -l /dev/mtd*
crw------- 1 root root 90, 0 Feb 16 20:39 /dev/mtd0
crw------- 1 root root 90, 1 Feb 16 20:39 /dev/mtd0ro
Se puede usar dd para leer y escribir en ellos, como en cualquier fichero.
Por ejemplo, leemos de mtd0. Está borrado así que son todo unos:
# dd if=/dev/mtd0 | hd
00000000 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000010 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
Escribimos lo que sea, por ejemplo Hello world!:
# echo "Hello world!" | dd of=/dev/mtd0
13 bytes copied, 0.000574479 s, 22.6 kB/s
Y funciona bien. Leemos y nos devuelve Hello world!.
# dd if=/dev/mtd0 | hd
00000000 48 65 6c 6c 6f 20 77 6f 72 6c 64 21 0a ff ff ff |Hello world!....|
00000010 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
Ahora escribirmos otra cosa distinta encima, para que veas cómo los datos se corrompen:
# echo "Overwrite doesn't work" | dd of=/dev/mtd0
23 bytes copied, 0.00103406 s, 22.2 kB/s
Al escribir encima, los bits que eran 1 sí han pasado a 0 pero los que eran 0 se han quedado como estaban:
# dd if=/dev/mtd0 | hd
00000000 48 64 64 60 67 20 61 64 60 20 64 21 00 73 6e 27 |Hdd`g ad` d!.sn'|
00000010 74 20 77 6f 72 6b 0a ff ff ff ff ff ff ff ff ff |t work..........|
Por eso te dicen que no uses dd para escribir en una Flash, que utilices flashcp.
Para borrar una flash se usa flash_erase.
# flash_erase /dev/mtd0 0 1
Erasing 4 Kibyte @ 0 -- 100 % complete
Limpia de nuevo, todo a 1:
root@raspberrypi:~# dd if=/dev/mtd0 bs=32 count=1 | hd -v
00000000 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
00000010 ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff |................|
JFFS2 y wear leveling
Vamos a ver cómo funciona JFFS2 (Journalling Flash File System version 2), un sistema de ficheros especialmente pensado para MTD. Soporta journaling (no pierde datos si se corta la alimentación), compresión al vuelo y wear leveling.
Empezamos por “formatear” el dispositivo con la opción -j:
# flash_erase -j /dev/mtd0 0 0
Erasing 4 Kibyte @ 7ff000 -- 100 % complete
Ese comando borra los sectores y escribe al principio de cada uno la siguiente cabecera:
00000000 85 19 03 20 0c 00 00 00 b1 b0 1e e4 ff ff ff ff |... ............|
Las estructuras de JFFS2 se definen en jffs2.h. Separamos los campos para entenderlo mejor:
85 19 <- jffs2
03 20 <- cleanmarker, accurate
0c 00 00 00 <- 12 bytes
b1 b0 1e e4 <- checksum
El 85 19 es el magic de JFFS2. Todas las estructuras de JFFS2 empiezan así. Son dos dígitos para detectar cuándo el endianness está al revés. En un sistema little endian 85 19 se lee como 0x1985.
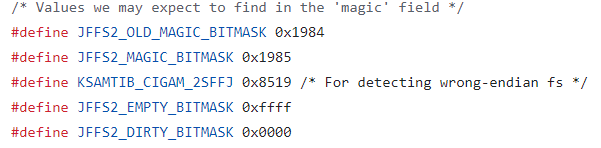
Atento al nombre de la constante. jffs2.h
El 03 indica que es una cabecera de tipo cleanmarker. Es decir, que el segmento se ha podido borrar bien y no parece defectuoso.
Aparte del 03 otros números frecuentes son el 01, entrada de directorio; y el 02 inodo (datos y metadatos de un fichero).
Luego viene la longitud, 12 bytes. Y finalmente cada nodo lleva uno o varios checksum.
JFFS2 está pensado para minimizar los ciclos de escritura-borrado. Eso lo consigue versionando todo. Un poco como git.
- Si alteras el contenido de un fichero no se modifica: se crea otra versión del inodo con los datos nuevos.
- Si borras un fichero no se borra: se crea otra versión de la entrada de directorio donde ese fichero ya no pertenece a ningún directorio.
- Si cambias los permisos de un fichero, crea otra versión del inodo con los permisos actualizados: pero el original no lo toca.
Te lo voy a enseñar de forma práctica. Imagina que montamos una memoria y vemos que hay un fichero llamado password:
# mount -t jffs2 mtd0 /mnt/flash
# ls -la /mnt/flash/
-rw-r--r-- 1 root root 4096 Feb 23 18:55 a_file
-rw-r--r-- 1 root root 4096 Feb 23 21:45 password
Si bien parece que el contenido de password ha sido editado:
# cat password
My password is: <redacted>
Por dentro, JFFS2 lo ha gestionado con cuatro estructuras. Las he marcado con colores diferentes.
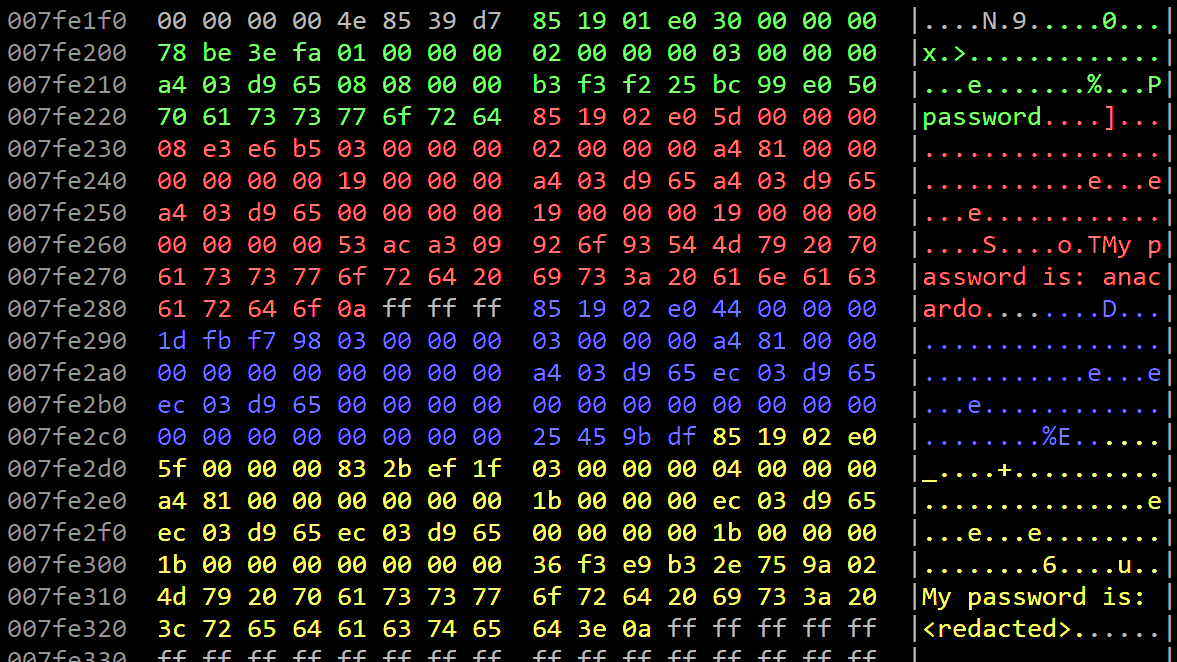
Análisis forense de un sistema JFFS2. EyC.
La primera, en verde, es de tipo direntry (porque el tercer byte es un 01). Estas estructuras direntry, o entrada de directorio,vinculan el nombre de un fichero con sus datos.
¿Te suena el directorio /lost+found en Linux, y los ficheros *.CHK o FOUND.000 en Windows? Cuando tienes inodos con datos válidos (no marcados como borrados) pero no hay ninguna entrada de directorio que los referencie se dice que están huérfanos. Eso es una inconsistencia. Como no sabes a qué fichero pertenecen o pertenecieron esos datos, los guardas en objetos perdidos.
Volviendo a la estructura direntry:
85 19 <- magic
01 e0 <- dir entry
30 00 00 00 <- 48 bytes
78 be 3e fa <- checksum
01 00 00 00 <- parent node
02 00 00 00 <- version
03 00 00 00 <- inode id
a4 03 d9 65 <- timestamp
08 <- name size: 8
08 <- type: regular file
00 00
b3 f3 f2 25 <- node crc
bc 99 e0 50 <- name crc
Data:
"password"
Con esos datos sabemos que:
- Es un fichero normal, por el type 8 (fs_types.h).
- Es la segunda versión de esta entrada.
- Cuelga del nodo
1(parent node). En este caso el directorio raíz. - Identifica a quien pertenecen los datos del inodo
3, que veremos a continuación.
Un sistema de ficheros trabaja como una estructura en árbol. Cada entrada de directorio es un nodo que a su vez cuelga de otro. Por eso tiene id padre.

Si no ves árboles por todos lados, no sabes Informática. Wikipedia.
La estructura en amarillo, abajo del todo, es el inodo 3. Al que hacía referencia la entrada anterior.
85 19 <- magic
02 e0 <- inode
5f 00 00 00 <- 95 bytes
83 2b ef 1f <- checksum
03 00 00 00 <- inode id
04 00 00 00 <- version
a4 81 <- mode: 0100 0644
00 00
00 00 <- uid: root
00 00 <- gid: root
1b 00 00 00 <- total file size
ec 03 d9 65 <- access date: 1708721132 (Friday, 23 February 2024 20:45:32)
ec 03 d9 65 <- modification date
ec 03 d9 65 <- change date
00 00 00 00 <- offset
1b 00 00 00 <- compressed size: 27
1b 00 00 00 <- data size: 27
00 <- compression alg: none
00
00 00
36 f3 e9 b3 <- data CRC
2e 75 9a 02 <- node CRC
Data:
"My password is: <redacted>"
Podemos deducir que:
- Este es el inodo
3(el cual vimos antes que tenía por nombre password). - Es la cuarta versión de este inodo.
- Se trata de un fichero normal con permisos
0644(-rw-r--r--). - Su propietario es root (owner id 0).
- Fue modificado a las 20:45:32.
- Tiene de 27 bytes de longitud.
- No está comprimido. De hecho, al ser tan corto comprimirlo resultaría en un mayor tamaño.
- Su contenido es
My password is: <redacted>.
La estructura en azul es la tercera versión, sin datos. En ella el fichero está vacío; como si lo hubieran truncado.
La estructura en rojo es la segunda versión. Sólo cambian algunas partes:
03 00 00 00 <- inode #
02 00 00 00 <- version
a4 03 d9 65 <- modification date: 1708721060 (Friday, 23 February 2024 20:44:20)
Data:
"My password is: anacardo"
En un análisis forense diríamos que:
el fichero se modificó a las 20:44:20, en ese momento contenía la contraseña en claro; sin embargo, fue sobrescrito segundos más tarde, a las 20:45:32, con intención de eliminar la información sensible.
Con el tiempo, cuando el espacio usado llegue a un umbral, el garbage collector acabará eliminando las versiones obsoletas y moviendo los datos actualizados a un sector aparte. Pero mientras tanto ahí están.
¿Por qué te cuento esto? Para que veas el efecto del wear leveling.
Aquí tenemos acceso directo a la memoria y podemos borrarla o escribir en cualquier sitio. Pero en un pendrive o un SSD, la NAND Flash está tras un chip, como vimos al comienzo del artículo. Y por supuesto hace wear leveling. Por eso es tan difícil eliminar la información en estos dispositivos, ni formateándolo varias veces. Salvo que los destruyas físicamente o estén cifrados.
Conclusión
Ahora que está tan de moda el IoT, ya puedes decir que sabes leer y escribir de una flash tanto directamente en SPI como a través del sistema operativo. Es más, no todo el mundo conoce ni mucho menos ha tocado el device tree de un dispositivo embebido.
También has visto cómo el wear leveling, necesario en cualquier dispositivo Flash, dificulta el borrado seguro. Y por qué guardar información confidencial en un pendrive es una mala idea.
Quedan por cubrir muchas cosas. Como el sistema UBI, que nos permitiría cifrar el sistema de ficheros sin perder la capacidad de journaling o wear leveling. Abajo te dejo algunos enlaces para que sigas mirándolo por tu cuenta.
Enlaces para profundizar
Otros artículos:
- Electrónica y Ciencia - El bus I2C a bajo nivel
- Electrónica y Ciencia - Conexión GPIO de Raspberry Pi 3
- Electrónica y Ciencia - Raspberry Pi como generador de frecuencias
Device tree:
- Raspberry Pi Documentation - Device Trees, overlays, and parameters
- Linux and the Devicetree
- Devicetree Specification
MTD Memory Technology Device:
- Linux Flash for Newbies: How Linux Works with Flash
- An Introduction to SPI-NOR Subsystem
- Investigation of degradation mechanisms and related performance concerns in 40nm NOR Flash memories
JFFS2 y UBI: