 Electronica y Ciencia
Electronica y CienciaAnálisis de las distribuciones de voto en Filmaffinity
- Distribución de las notas
- Recogida de datos
- La película típica
- Sobrevaloradas e infravaloradas
- Listas de recomendación
Vamos a hablar de cine, también hablaremos de programación, de estadística y tratamiento de datos, todo ello -te lo aseguro- relacionado con el cine. El gusto es algo muy subjetivo, por supuesto, pero hay gustos más y menos comunes así que, por una vez, me vais a permitir ser vuestro crítico de cine.
¿Conoces la web Filmaffinity? No es nueva, y no tengo nada que ver con ella, pero aún así me gustaría presentártela. Déjame que escriba primero una reseña, para que puedas entender todo este artículo que gira en torno a ella.
Para quien no la conozca digamos que es una web muy bien hecha, ideal para descubrir más películas que te puedan gustar. De manera similar a la idea de Last.fm para música, en función de tus votaciones busca usuarios con gustos similares a los tuyos “almas gemelas” y te los presenta para que puedas ver qué más películas han votado estos. Esta era la idea original hace algunos años, junto con la navegación cruzada (pinchas en un actor y salen su películas, en una película y te lleva a su ficha, entre los datos puedes pinchar en su director y aparecen sus películas, en un género, en una lista, etc). Recientemente han incorporado otras funciones muy interesantes.
Distribución de las notas
Evidentemente una de las funciones básicas de la página es votar una película (o una serie, o un documental). Se puede votar en puntos enteros del 1 al 10. Lo primero que caracteriza una película es su calificación. Lo que me gustó de Filmaffinity es que no sólo muestra la nota, sino que muestra también algo que para mi es muy importante y que dice mucho más que la nota: la distribución de los votos.
Vamos a fijarnos en dos buenas películas: El señor de los anillos 3: El retorno del rey y En el nombre del padre. Ambas son películas muy buenas un 8.11 y 8.16 respectivamente. Sin embargo sus distribuciones se diferencian mucho. Aunque las podéis ver en la página las pego aquí por comodidad:
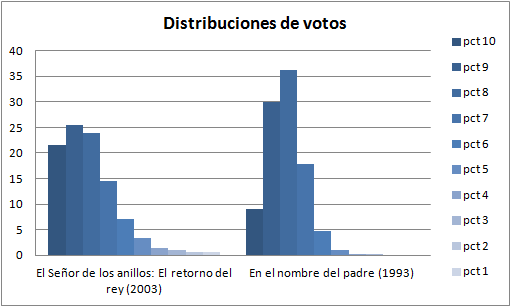
El retorno del rey es una película mayoritaria, bien hecha y para todos los públicos. Es cierto que a algunos sectores como a los seguidores de Tolkien les resultará especialmente buena (o mala dependiendo de lo tolerantes que estén dispuestos a ser con la adaptación). Una historia fantástica donde el bueno es muy bueno y el malo muy malo, al final triunfa el bien sobre el mal y todos felices. Por lo general este tipo de historias gustan, de ahí tenemos muchos dieces, nueves y ochos. Hay también quien no tolera los fallos de guión, quien esperaba más o quien simplemente le aburren estas historias por lineales y repetitivas. Por eso tenemos las notas bajas, hay bastantes votos por debajo del 6.
Una pregunta que nos planteamos en este artículo es ¿por qué alguien ve una película y le acaba poniendo un 1? ¿Decepción? ¿Rabia? Si desde el principio piensas que es tan mala que le vas a poner un 1 ni siquiera la ves.
En el nombre del padre en cambio, es una película más cruda ambientada en Irlanda de Norte en tiempos del IRA y basada en hechos reales. La historia no es bonita ni tiene que serlo, porque una historia dura no hace que una película sea mala. Ahí tenemos la mayoría de nueves y ochos. También unos pocos dieces, quizá de alguien a quien le gusta el género especialmente, sólo hay que leer las críticas. Pero lo más importante de todo es ¿cuantos unos tiene, cuántos doses? Ninguno.
El retorno del rey es una película que ha visto mucha gente, tiene casi 133000 votos. La ha visto gente que le gusta este tipo de historias y gente que no, por eso el voto está más distribuido. En el nombre del padre no fue tan mediática cuando salió ni es tan popular. Tiene 53000 votos, menos de la mitad. Sí es conocida entre gente que le gusta el cine, por eso la concentración del voto alrededor de la media.
No hay que perder de vista que muchos de los votos se originan a partir de recomendaciones de la propia página, a través de las almas gemelas que se deducen de tus votaciones. Luego en parte también estamos evaluando de manera directa la bondad del algoritmo de recomendación.
Vamos a ver dos películas también populares pero con otra distribución muy distinta. Dos tontos muy tontos (1994) y Ace Ventura: Operación África (1995).
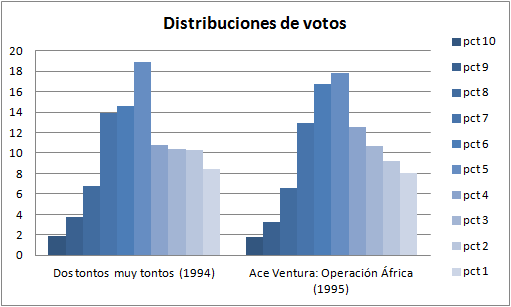
¿Por qué pasa esto? Es lo que nos preguntábamos hace unas líneas. La mayoría de la gente vemos películas que pensamos que nos van a gustar. Si antes de verla creyéramos que le vamos a poner un 1, no perderíamos el tiempo y directamente veríamos otra cosa. Se me ocurren varios motivos:
- Popularidad. La película llega a tanta gente que acaba por verla (y votarla) mucha gente que no es su público objetivo. Recomendaciones de amigos, películas que se ven en fiestas, en medios de transporte, etc.
- Publicidad engañosa. Un trailer que no refleja la película y fija unas expectativas mucho más altas de lo que se merece. Por ejemplo este sería el trailer de 2001: Odisea en el espacio si se fuera a estrenar este verano.
- Decepción. La película es de un actor o un director que nos suele gustar, pero esta vez no ha seguido su línea.
- Obligación. Películas que vemos “forzados” porque les gustan a los demás, novia, novio, grupo de amigos…
- Voto de oídas. Votos que se emiten sin haber visto la película, basados en lo que la gente dice.
- Estado de ánimo. Vemos una película en un momento en que hubiera sido mejor ver otra.
- Sobrevaloración. Alguien opina que la película merece un 6, pero la nota media que tiene es de 8. Entonces este no vota 6 sino que vota 1 para intentar compensar esa sobrevaloración que, a su juicio, tiene.
- Voto irracional. No me gusta tal actor, o tal director y a todo lo que haga, sin verlo, le voy a poner mala nota.
Fijaos en otra distribución de una serie menos conocida, que tiene menos votos y precisamente por eso son de sus adeptos:
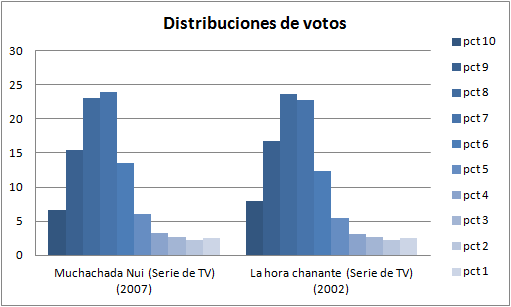
Por supuesto esas colas de unos y doses son señal de que el humor absurdo de estas series no gusta a todo el mundo que la ve.
Recogida de datos
Para profundizar un poco más en el estudio vamos a necesitar tener los datos más a mano para poder operar con ellos. En este apartado voy a explicar cómo bajarse las votaciones de todas las películas en Filmaffinity de forma que el servidor sufra lo menos posible.
Para que os hagáis una idea, en el momento de escribir este artículo la base de datos de Filmaffinity cuenta con unas 43000 películas con más de 10 votos (las que no llegan a 10 votos no tienen calificación). Cada película está identificada por un índice de 6 dígitos. Por desgracia los índices no son correlativos sino que parecen aleatorios. Luego debemos obtener primero los índices de todas las películas, y posteriormente solicitar la página con la ficha y obtener título, número de votos y distribución de votos.
Lo primero que hay que tener en cuenta al extraer tantos datos de una web es espaciar las peticiones para no saturar el servidor. Claro que podemos lanzar un programa multi-hilo que se baje las 43000 películas en unos minutos, pero eso no sería muy distinto de atacar la página. Lo mejor que nos puede pasar es que filtren la IP por exceso de peticiones, y lo peor es que tiremos el servidor o lo hagamos funcionar más lento por el exceso de carga. Dependerá de los sistemas IPS y cache que tengan configurados. Como no lo sabemos hay que evitarlo a toda costa.
Lo segundo que hay que tener en cuenta es que todas las peticiones que hagamos sean útiles. Por ejemplo, si sé que cada película tiene un índice de 6 cifras, bastará que pida todas las páginas desde 000001 a 999999. Eso, además de ser una pérdida de tiempo, hará saltar las alarmas de cualquier sitio web. A priori es imposible saber cuantas películas hay, pero si hubiera 45000 sólo 1 de cada 22 peticiones sería viable.
El script siguiente hace una petición por segundo, por tanto tardaremos unas 24 horas en descargar toda la información. Como siempre, primero pego el script y luego lo comentamos.
#!/usr/bin/perl -w
use strict;
use warnings;
use HTML::Entities;
# Descarga la página de todas las películas de Film Affinity.
# En lugar de la descarga al azar, que provoca muchas colisiones
# se prefiere una descarga sistemática.
$| = 1;
my $wget = 'wget -O - -q';
# Leemos el fichero con la base de datos, para saber los ID que ya tenemos.
my $fich_data = "peliculas.dat";
my %tenemos; # para no repetir
open my $fh, "< $fich_data";
while (my $linea = <$fh>) {
my @campos = split /\|/, $linea;
$tenemos{$campos[0]}++;
}
close $fh;
# Ahora vamos letra por letra viendo cuántas páginas tiene
my @letras = qw/* 0-9 A B C D E F G H I J K L M N O P Q R S T U V W X Y Z/;
for my $letra (@letras) {
print "$letra... ";
my $html = `$wget http://www.filmaffinity.com/es/allfilms_${letra}_1.html`;
redo if not $html;
my ($max) = $html =~ m{1 de (\d+)</td>};
redo if not $max;
print "$max páginas.\n";
# Bajamos cada página
for my $pagina (1..$max) {
my $html = `$wget 'http://www.filmaffinity.com/es/allfilms_${letra}_${pagina}.html'`;
next if not $html;
# Dentro de la página, obtenemos las pelis que hay
# Pero sólo las que tienen rating,
# Para discriminarlas fácilmente hacemos una transformación previa,
# que consiste en dejar las tablas en una sola linea y buscar que esa linea
# contenga 'ratings'
$html =~ s/\n//g;
$html =~ s/table/\n/g;
my @ids = $html =~ m{<a href="/es/film(\d+).html">.*ratings/\d+\.gif}g;
next if not @ids;
# Seleccionamos una de ellas
# que no haya salido
for my $id (@ids) {
next if not $id;
print "\n$letra $pagina/$max $id: ";
(print "La tenemos" and next) if $tenemos{$id};
$tenemos{$id}++;
# Espera de cortesía
sleep 1;
# Obtenemos sus datos
$html = `$wget http://www.filmaffinity.com/es/film$id.html`;
next if not $html;
my ($titulo) = $html =~ m{<title>\s*(.+)\s+- FilmAffinity</title>};
my ($votos) = $html =~ m{>\s*([\d\.]+)\s*votos</div>};
my @pctvotos = $html =~ /rat10=([\d\.]+)&rat9=([\d\.]+)&rat8=([\d\.]+)&rat7=([\d\.]+)&rat6=([\d\.]+)&rat5=([\d\.]+)&rat4=([\d\.]+)&rat3=([\d\.]+)&rat2=([\d\.]+)&rat1=([\d\.]+)/;
# Si no tiene suficientes votos o hubo un error toma otra
$titulo and $votos and @pctvotos or print " Error ($titulo) ($id)" and next;
$votos =~ s/\.//g;
$titulo =~ s/\|//g;
$titulo = decode_entities($titulo);
print " $votos -> $titulo";
# Como separador no podemos usar ; porque es probable que aparezca en
# algún título
local $" = '|';
# Abrimos y cerramos, para sincronizar en el momento
open my $fh, ">> $fich_data";
print $fh "$id|$titulo|$votos|@pctvotos\n";
close $fh;
}
}
}
print "\n";
Entre las líneas 1 a 19 cargamos lo necesario y definimos algunas variables: el fichero de salida, que será una base de datos tipo CSV llamada peliculas.dat.
Hasta la línea 26 leemos el fichero de salida y almacenamos en un hash los identificadores de las películas que ya hemos bajado para, en caso de interrumpir el programa, omitir la petición y no duplicarlos.
En la línea 30 empieza el bucle principal. Recorreremos todas las letras de la clasificación de películas. Supongamos que empezamos por la A. En la línea 44 pedimos la primera página que será http://www.filmaffinity.com/es/allfilms_A_1.html. Por supuesto la petición puede fallar por diversas causas, para eso está la línea siguiente. Esta vez, en caso de fallo lo volvemos a intentar, otras veces continuamos con el siguiente. Es posible que necesitemos ejecutar dos o tres veces el programa para asegurarnos de que tenemos los datos de todas las películas.
En la linea 36 obtenemos cuántas páginas hay bajo esta letra. Y en la línea 42 comenzamos a bajarnos todas las páginas de esa misma letra desde la 1 hasta la máxima que haya.
Como el formato de la lista de películas se hace con tablas, para obtener información tendríamos que interpretar el árbol HTML pero una forma más sencilla y rápida es deshacer el formato tabular. Lo hacemos en las líneas 51 y 52. He aquí un ejemplo, partimos de esto:
...cosas...
<table>
<tr>
<td>Película 1</td>
<td>Director 1</td>
<td>Nota 1</td>
</tr>
</table>
...cosas...
<table>
<tr>
<td>Película 2</td>
<td>Director 2</td>
<td>Nota 2</td>
</tr>
</table>
...cosas...
Si eliminamos todos los saltos de línea deshacemos el formato tabular y lo convertimos en lineal.
...cosas...<table><tr><td>Película 1</td><td>Director 1</td><td>Nota 1</td></tr></table>...cosas...<table><tr><td>Película 2</td><td>Director 2</td><td>Nota 2</td></tr></table>...cosas...
A continuación elegimos algo que pueda servir como separador entre una película y otra: “table” podría servir. Lo sustituimos por un salto de linea.
...cosas...<
><tr><td>Película 1</td><td>Director 1</td><td>Nota 1</td></tr></
>...cosas...<
><tr><td>Película 2</td><td>Director 2</td><td>Nota 2</td></tr></
>...cosas...
Ahora cada película está en una línea. Este método es muy práctico para analizar ficheros tabulares utilizando tr y grep. Definiendo el carácter de separación de campos y de separación de registros se consigue un resultado similar en Bash o AWK.
Y ya que tenemos cada película en una línea, en la línea 53 obtenemos el identificador sólo de las que contengan la palabra “rating”, porque esas son las que tienen más del mínimo de 10 votos.
Vamos a la línea 58. Por cada uno de los identificadores (id) en la página comprobamos que no lo habíamos solicitado previamente. El sleep de la 68 es un retardo de cortesía, y ya hemos dicho que es muy importante. Solicitamos a Filmaffinity la ficha correspondiente a este registro.
En las líneas 74 a 76 buscamos las cadenas que nos interesan, que son
- El título de la página, donde viene el título y el año de la película.
- El número de votos.
- La distribución en porcentajes. Hace un tiempo aquí podían verse los votos absolutos, pero ahora sólo aparecen porcentajes, por eso necesitamos también el dato de votos totales.
| A continuación eliminamos el separador de miles del número de votos. Aunque podríamos escaparlo, Por comodidad nos aseguramos de que el título no contenga el carácter “ | ”, que es el que hemos elegido como separador de campos. Y decodificamos los caracteres especiales que pudiera tener el título. |
Finalmente, en la línea 93 guardamos la información en el fichero de salida con este formato:
id|titulo|10|9|8|7|6|5|4|3|2|1\n
La película típica
Ya tenemos nuestro fichero peliculas.dat. Vamos a empezar a analizarlo con Matlab aunque para reordenar y visualizar las listas continuaremos en Excel.
Lo primero es cargar el fichero, puesto que tiene tanto campos de texto como numéricos utilizaremos textscan.
fh = fopen('peliculas.dat');
C = textscan(fh, '%f %s %f %f %f %f %f %f %f %f %f %f %f', 'delimiter', '|' );
fclose(fh);
Aquí hay que tener en cuenta leer todos los campos como float, incluido el número de votos que es entero, o bien transformarlos después. De lo contrario perderemos precisión en las operaciones ya que Matlab operará todos por defecto como si fueran enteros.
C, el resultado, es un array de celdas mixto. De lo que hemos cargado, para operar no nos interesan los títulos de las películas ni los identificadores de Filmaffinity (aunque también los incluiremos). Construimos una matriz con los datos numéricos que son el identificador, los votos y el porcentaje de votos.
votos = [C{1} C{3} C{4} C{5} C{6} C{7} C{8} C{9} C{10} C{11} C{12} C{13} ];
Dibujamos primeramente un histograma para ver cómo se distribuye el número de votos. 43000 películas son muchas, así que vamos a buscar un criterio que nos permita diferenciar entre películas conocidas de minoritarias para intentar reducir el número.
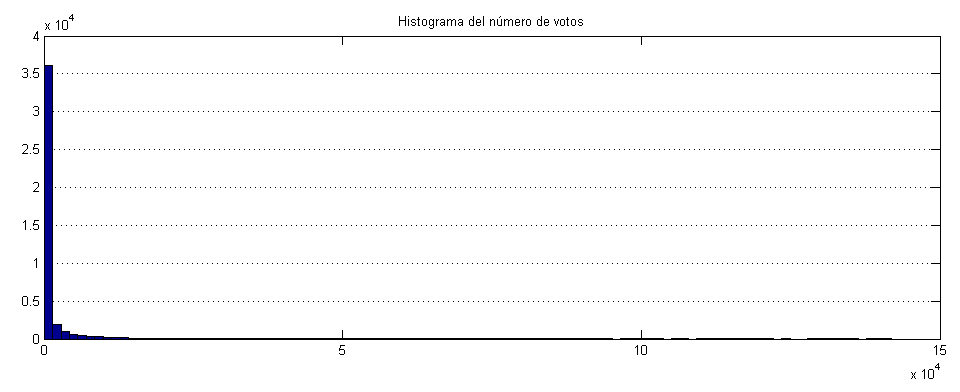
Haced click en cualquiera de las imágenes para ampliarlas. ¿Qué significa este gráfico? Pues que Filmaffinity alberga muchísimas películas que sólo conocen unas pocas personas. Es una distribución muy típica de páginas especializadas donde hay muchas cosas muy específicas que sólo se conocen en círculos concretos. La buena noticia es que podremos reducir mucho el número de datos sin temor a dejarnos fuera películas conocidas.
Con una escala tan amplia, si queremos explorar las barras inferiores tenemos que tomar logaritmos en el eje Y.
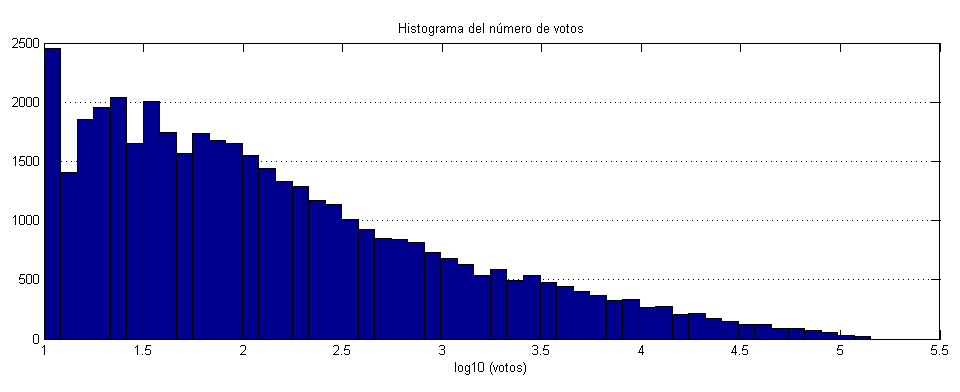
Ahora se ve un poco mejor. Podríamos decir que el máximo está en 2, y a partir de ahí decrece. Pero no hay realmente un valle, ni un descenso brusco, sino una cola que decrece gradualmente a cero. Significa que Filmaffinity tiene un público muy variado en cuanto a su criterio. Que cada persona ha visto y votado películas diferentes. Si hubiera público especialista y público erudito veríamos dos máximos, no es el caso.
Otro parámetro que podemos estudiar es la distribución de notas. Dado el vector con los porcentajes, la nota se calcula como un producto escalar:
nota = 10*pct10 + 9*pct9 + ... + 1*pct1 / 100
En realidad no habría que dividir entre 100, sino entre la suma de los coeficientes que puede no sumar 100 por los errores de redondeo:
nota = (10 9 ... 1) . (pct10 pct9 ... pct1) / sum(pct10 pct9 ... pct1)
Como el vector de porcentajes tiene dos dimensiones hay que replicar el multiplicador tantas veces como sea necesario. Así calculamos el vector de notas de todas las películas (importante sumar en la segunda dimensión -por filas-). En inglés, el producto escalar se llama dot product por eso la función de Matlab se llama dot:
>> mul = 10:-1:1;
>> ratios = votos(:,3:12);
>> notas = dot(ratios, repmat(mul, length(ratios),1),2) ./ sum(ratios,2);
La productoras sacan multitud de películas todos los años. La mayoría serán mediocres, algunas serán malas, otras serán mejores. Si graficamos un histograma con la distribución de las notas esperaríamos que se pareciera a una distribución normal. Pero no es del todo así:
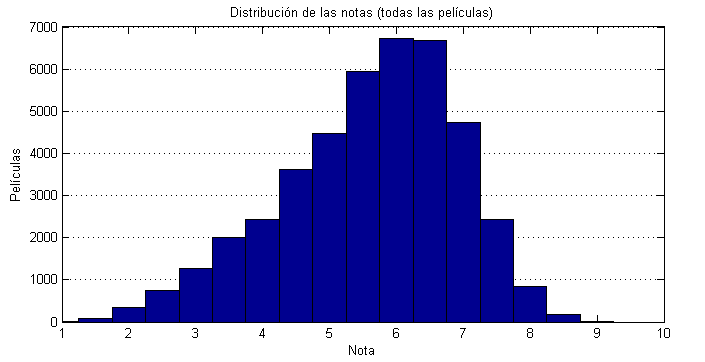
La mayoría de la gente no ve todas las películas, ni siquiera una muestra aleatoria. Conocemos películas en función de los círculos que frecuentemos, y de entre todas las que conocemos elegimos ver aquellas que creemos nos van a gustar mas. Por eso la distribución está desplazada hacia notas mayores.
Las notas más frecuentes son 5, 6 o 6.5. El porcentaje de 3, 4 o 5 no es nada desdeñable. Vamos a tomar ahora películas populares, por ejemplo las que tengan más de 20000 votos:
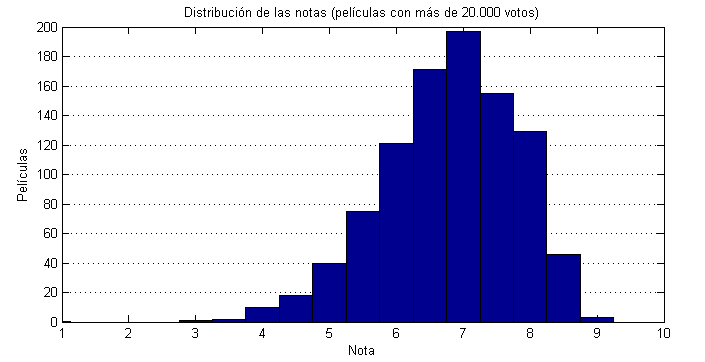
Las notas mayores son más frecuentes que las menores, y hay un corte muy pronunciado por debajo del 5. Es obvio que entre las 43000 películas muchas son malas a rabiar (digamos que son para un público muy específico). Y otra cosa que también es lógica, mientras mejor sea la película más probable es que se haga popular. Por eso a medida que nos vamos quedando con las películas que tienen más votos, la nota media es mayor:
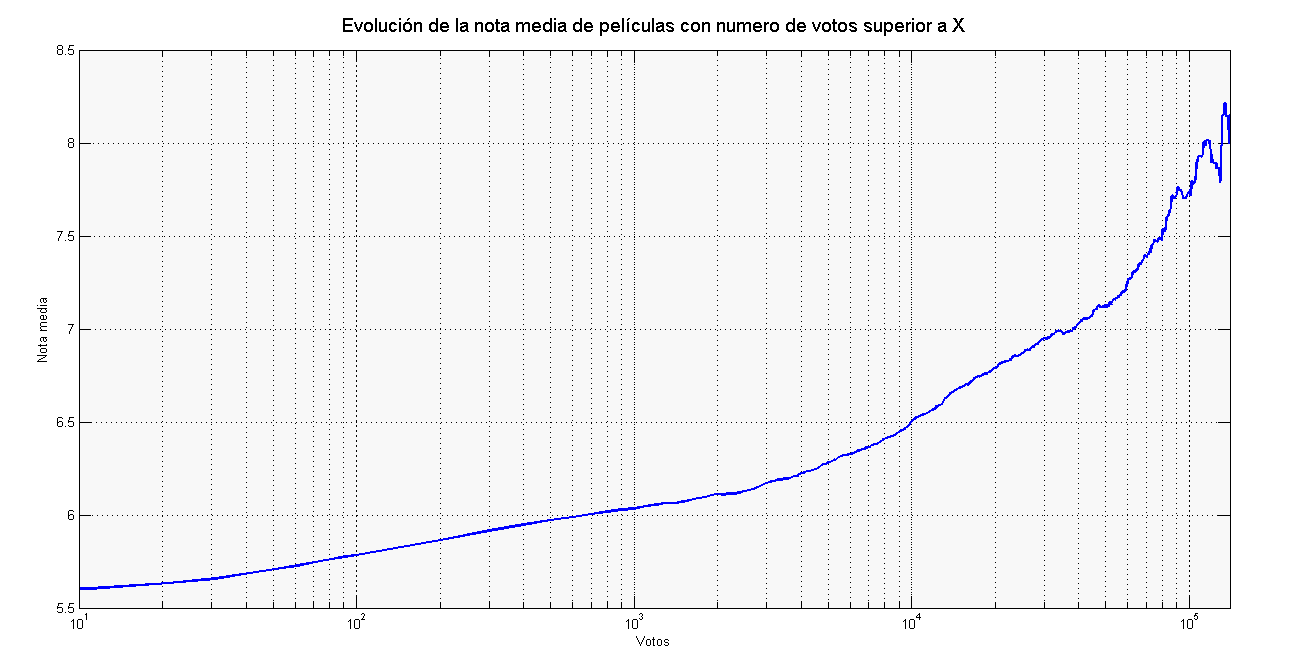
Ya habíamos visto cómo hay muchísimas películas con pocos votos, y unas pocas con muchos votos. Por ejemplo, el mínimo es 10 votos, mientras que las 10 películas más votadas tienen diez mil veces más:
- 141.961 Forrest Gump (1994)
- 139.653 Matrix (1999)
- 138.985 El Señor de los anillos: La comunidad del anillo (2001)
- 138.252 Pulp Fiction (1994)
- 135.238 La vida es bella (1997)
- 134.232 Gladiator (El gladiador) (2000)
- 132.699 El Señor de los anillos: El retorno del rey (2003)
- 132.556 El club de la lucha (1999)
- 131.305 Titanic (1997)
- 130.371 Algo pasa con Mary (1998)
Al quedarnos sólo con las que tienen un mínimo de votos estamos descartando tanto las películas que no lleguen a ese número como sus votos. Lo siguiente es un gráfico del porcentaje de películas y de votos que descartamos al eliminar las películas que no lleguen a un mínimo:
>> nvotos = [1:10:100,100:100:150000];
>> [pv,pp] = ratiovotos(V,nvotos);
>> plot(nvotos, pv, nvotos, pp);
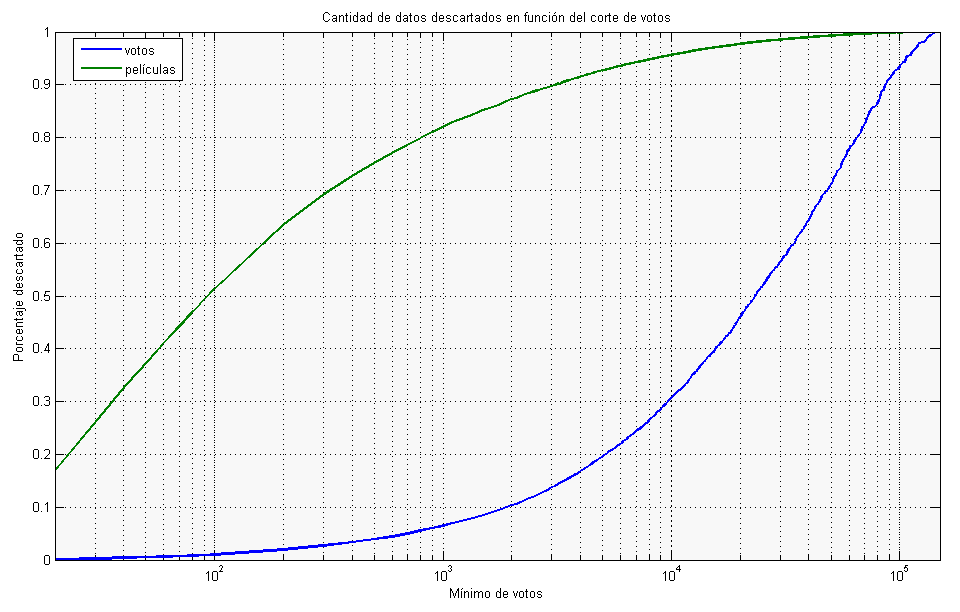
Si nos quedáramos sólo con las que tienen más de 2000 votos, estaríamos descartando el 87% de todas las películas, pero sólo habríamos perdido el 10% de los votos. Si os interesa, al final del artículo tenéis los archivos con funciones de Matlab para generar estos gráficos.
Sobrevaloradas e infravaloradas
Para continuar el análisis nos vamos a quedar con las que tienen más de 20000 votos, que además coincide con que son las mil primeras películas (968 exactamente). Vamos a multiplicar la columna de los votos por cada porcentaje y así sabremos cuantos dieces, nueves, etc. tienen. Después de contar cuantos votos hay de cada valor, lo normalizamos a 100 para dibujar un gráfico:
>> vot20k = votos(votos(:,2) > 20000,:);
>> nums = vot20k(:,3:12) .* repmat(vot20k(:,2),1,10);
>> sum(nums)/sum(sum(nums)) * 100
ans =
6.7107 13.7383 21.3029 22.9011 16.7085 8.9657 4.2818 2.7920 1.5945 1.0046
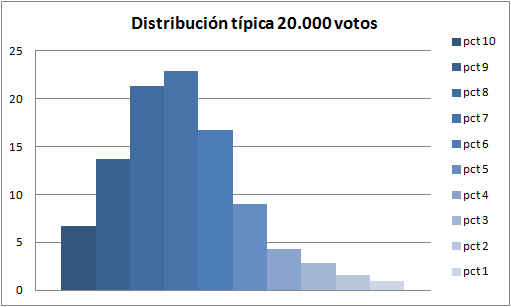
La media es casi 7. Lo que quiere decir que cuando votamos lo más normal es que pongamos un 7 o un 8. Es menos habitual poner un 9 o 10, y los unos son casi una excepción. A continuación vamos a hablar justamente de películas excepcionales.
Si invertimos la distribución típica tenemos una idea de lo relevante que es ver un 1 en estas votaciones.
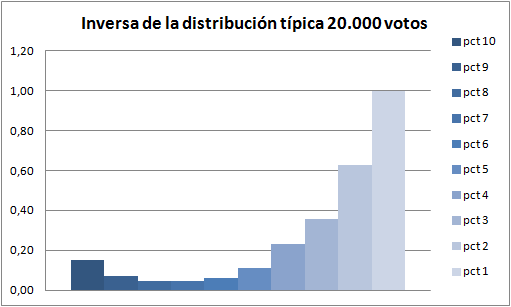
Cuando alguien escribe sobre una tienda o un producto, es más frecuente hacerlo para quejarse que para decir que todo ha ido bien. Aquí pasa lo mismo, esperamos ver una película buena (alrededor de 7), por lo que la gente dice; y sin embargo alguien opina que merece una nota más baja.
Vamos a ver qué pasa si ponderamos la distribución original multiplicándola por la inversa. Ocurrirá que las películas “típicas” (siguen la distribución anterior) tendrán una nota de 5 normal. Las que tengan más unos y doses bajarán mucho de nota y aquellas con muchos dieces subirán.
Así por ejemplo, Matrix (1999) bajará de un 7.90 a un 7.22. Unos opinarán que efectivamente, estaba sobrevalorada, otros que bajarle la nota es un crimen. Pero recordad que no estamos midiendo si la película es buena o mala, sino cómo es de excepcional. Antes la nota media era 7 y Matrix tenía un 7.90. Ahora hemos eliminado ese sesgo y aún tiene un 7.22, sigue siendo una película excepcional.
Las películas típicas serían aquellas cuya nota corregida es 5. Ente estas encontramos Enemigo público (1998), Soy leyenda (2007), Troya (2004), Los cazafantasmas (1984), Resacón en Las Vegas (2009) o Todo sobre mi madre (1999). Tal vez opines que alguna de estas películas es una obra maestra. Pero estadísticamente dejan indiferente a quienes las han votado. La última, es especialmente sangrante ya que pasa de tener un 7.07 a 5.20. Es una tónica general en películas de Pedro Almodóvar. Como se suele decir o te encantan, o las odias, y una métrica que penaliza los 1 y 2 perjudica notablemente a este tipo de películas.
Para poder ordenarlas y sacar conclusiones definimos lo que vamos a llamar índice de sobrevaloración. Será una función de la diferencia entre la nota que tiene y la que nos ha salido con la corrección. Además vamos a ponderar la diferencia y cuanto mayor fuera la nota anterior, más alto será este índice. Por ejemplo, si baja de un 7 a un 5 son dos puntos; si baja de 10 a 8 también son dos puntos, pero para mí ha perdido más la segunda que la primera porque partía de una nota más alta. Si N es la nota original y Nc la nota corregida, el índice de sobrevaloración sería:
\[I_{Sobr} = \frac{N-N_c}{10-N}\]Por comodidad lo expresamos como porcentaje.
Listas de recomendación
Ya tenemos los datos cargados en Excel y definidas las formulas para nuestras métricas. Ahora vamos a ordenar para hacer listas.
Siguiendo el apartado anterior, empezaremos por las películas (omito las series) más “sobrevaloradas” en Filmaffinity:
- 73,9% Dogville (2003)
- 71,3% Mulholland Drive (2001)
- 66,7% El árbol de la vida (2011)
- 64,0% Todo sobre mi madre (1999)
- 63,4% Bailar en la oscuridad (2000)
- 61,5% La pasión de Cristo (2004)
- 59,2% The Rocky Horror Picture Show (1975)
- 59,1% [•REC] (2007)
- 58,8% Elephant (2003)
- 58,6% Miedo y asco en Las Vegas (1998)
- 58,6% Funny Games (Juegos divertidos) (1997)
- 58,0% Moulin Rouge (2001)
- 55,7% Torrente, el brazo tonto de la ley (1998)
- 55,6% Mujeres al borde de un ataque de nervios (1988)
- 55,5% La mala educación (2004)
Como ya habíamos previsto algunas son películas controvertidas, violentas, otras son absurdas, o “para chicas”, no voy a decir si a mi me parecen buenas o malas, pero desde luego hay mucha gente que las odia, tanta como gente que le encantan. Desde luego, si quieres ver algo que no te deje igual lo mejor es ver alguna de esta lista para saber de qué bando estás.
Pero al igual que hay películas “sobrevaloradas”, también las hay infravaloradas. Estas serían las que tienen menos unos y más dieces de lo normal. Aquí tenéis las quince primeras:
- -26,3% Cadena perpetua (1994)
- -21,1% Uno de los nuestros (1990)
- -21,1% 12 hombres sin piedad (Doce hombres sin piedad) (1957)
- -19,8% La ventana indiscreta (1954)
- -19,7% El apartamento (1960)
- -19,4% El golpe (1973)
- -18,9% Senderos de gloria (1957)
- -18,3% La gran evasión (1963)
- -16,8% La soga (1948)
- -15,6% Con la muerte en los talones (1959)
- -14,2% El tercer hombre (1949)
- -14,1% Rebeca (1940)
- -14,0% En el nombre del padre (1993)
- -13,5% Perdición (1944)
- -13,4% El Padrino. Parte II (1974)
- -12,9% Testigo de cargo (1957)
- -12,9% Alguien voló sobre el nido del cuco (1975)
- -12,7% American History X (1998)
- -11,9% Con faldas y a lo loco (1959)
- -11,8% Toro salvaje (1980)
Todo el análisis es un artificio matemático, y sin embargo no puedo estar más de acuerdo con esta lista. Si quieres recomendar una película estas son las que, al menos, no van a decepcionar. Me explico. En el caso de Cadena perpetua o Uno de los nuestros, que tienen 114.000 y 75.000 votos, en el momento de escribir este artículo no tienen -hasta donde podemos saber, dado que los datos sólo tienen un dígito decimal- ni un sólo 1 o 2. De 114000 personas que la han visto (que no son pocas, el máximo es 142000 votos de Forrest Gump) nadie ha votado 1 o 2, contando con que estas dos son películas largas, sin efectos especiales, sin finales espectaculares, todo guión y como la vida misma. Me pregunto quién pudo poner 1 a Doce hombres sin piedad pero es significativo que no tenga ni 2 y 3. Eso, para mi, tiene más mérito que tener muchos 7 u 8.
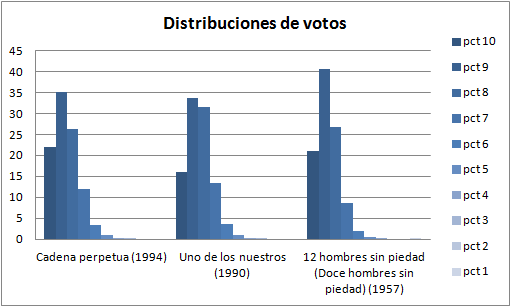
Por ahora ya está bien, lo terminamos aquí. Os dejo otras listas obtenidas al ordenar los datos con diferentes criterios. Y si queréis hacer vuestros experimentos o ver cómo está hecho el Excel os recuerdo que al final tenéis un enlace a los programas y archivos escritos durante la elaboración de este artículo.
Las más votadas:
- 141961 Forrest Gump (1994)
- 139653 Matrix (1999)
- 138985 El Señor de los anillos: La comunidad del anillo (2001)
- 138252 Pulp Fiction (1994)
- 135238 La vida es bella (1997)
- 134232 Gladiator (El gladiador) (2000)
- 132699 El Señor de los anillos: El retorno del rey (2003)
- 132556 El club de la lucha (1999)
- 131305 Titanic (1997)
- 130371 Algo pasa con Mary (1998)
- 129973 Kill Bill: Volumen 1 (2003)
- 124816 La naranja mecánica (1971)
- 121921 El Señor de los anillos: Las dos torres (2002)
- 121455 El silencio de los corderos (1991)
- 120771 El sexto sentido (1999)
La lista de mejor valoradas la podéis ver en Filmaffinity, así que os pego las mejor valoradas según la nota corregida:
- 9,14 El Padrino (1972)
- 9,05 El Padrino. Parte II (1974)
- 8,96 12 hombres sin piedad (Doce hombres sin piedad) (1957)
- 8,94 Cadena perpetua (1994)
- 8,86 Testigo de cargo (1957)
- 8,85 El golpe (1973)
- 8,79 La lista de Schindler (1993)
- 8,79 El apartamento (1960)
- 8,78 Senderos de gloria (1957)
- 8,76 Tiempos modernos (1936)
- 8,75 Ser o no ser (1942)
- 8,75 Uno de los nuestros (1990)
- 8,74 El gran dictador (1940)
- 8,74 Perdición (1944)
- 8,72 El crepúsculo de los dioses (1950)
Las que más dieces tienen:
- 54487 El Padrino (1972)
- 38158 Pulp Fiction (1994)
- 35770 El Padrino. Parte II (1974)
- 35162 La vida es bella (1997)
- 31844 La lista de Schindler (1993)
- 28530 El Señor de los anillos: El retorno del rey (2003)
- 26835 La naranja mecánica (1971)
- 25088 Cadena perpetua (1994)
- 24461 El Señor de los anillos: La comunidad del anillo (2001)
- 23991 Forrest Gump (1994)
- 22667 El club de la lucha (1999)
- 22344 Matrix (1999)
- 21144 Blade Runner (1982)
- 19873 El Señor de los anillos: Las dos torres (2002)
- 19471 Amelie (2001)
Las que más unos:
- 8549 Dos tontos muy tontos (1994)
- 6625 El proyecto de la Bruja de Blair (1999)
- 5843 Torrente 3: El protector (2005)
- 4852 Waterworld (1995)
- 4819 Ace Ventura: Operación África (1995)
- 4532 Independence Day (1996)
- 4479 Scary Movie (2000)
- 4305 Catwoman (2004)
- 4114 Dr. Dolittle (1998)
- 4089 Crepúsculo (Twilight) (2008)
- 4078 Austin Powers: Misterioso agente internacional (1997)
- 4074 Misión imposible 2 (M:I-2) (2000)
- 4014 Batman & Robin (1997)
- 3027 American Pie (1999)
- 2972 Sé lo que hicisteis el último verano (1997)
En este enlace encontraréis el siguiente contenido:
- El artículo en sí en formato texto y las imágenes.
- El programa en Perl y el fichero resultante películas.dat con los datos a 08/08/2012.
- Los ficheros .m de Matlab para el cálculo de los gráficos.
- El Excel con los datos cargados y procesados, filtros y cálculos necesarios.