 Electronica y Ciencia
Electronica y CienciaConvolución de dos imágenes: Homógrafos UTF
- Los Homógrafos
- El producto de convolución
- Preparación
- Fase de calibrado
- Fase de comparación
- Aplicación
- Aplicaciones
En una entrada anterior os decía que en breve presentaría una aplicación de la transformada de Fourier en dos dimensiones. Pues bien, como decíamos ayer, voy a utilizar la transformada, y más concretamente multiplicar dos transformadas, para encontrar patrones dentro de una imagen. Lo que técnicamente se llama Template Matching.
Los Homógrafos
La idea original de lo que aquí llamo Homógrafos no es mía, sino que me la sugirió hace años un compañero de trabajo a quien le agradezco que me permita usarla en este blog.
Se dice que dos palabras son homógrafas cuando se escriben igual aunque se lean diferente. A lo largo de este artículo vamos a utilizar el juego de caracteres superiores de UTF para encontrar letras extranjeras, o símbolos que se parezcan a las letras ASCII. Por ejemplo una omicrom minúscula puede pasar por una ‘o’ latina o una Gamma mayúscula por una F en los tipos sin serifa. Con estos símbolos “raros” pero visualmente iguales a las letras compondremos palabras que, en muchos programas, se ven casi idénticas a las palabras normales pero que en realidad no lo son.
Se trata de tomar un carácter UTF y compararlo automáticamente con las letras de la a a la z para comprobar si se parece a alguna letra. No tiene, en principio, por qué ser idéntico, puede ser más ancho o más estrecho, estar situado un poco más arriba o más abajo en el renglón, tener una tilde o un apéndice, el trazo más fino, etc.
Por supuesto los resultados dependen en gran medida de la tipografía, sin embargo en las tipografías más utilizadas funciona.
El producto de convolución
En realidad la búsqueda de homógrafos es sólo una excusa para hablaros de un método que tal vez no sea óptimo para este problema pero que se utiliza a diario en el reconocimiento de imágenes por ordenador: la convolución de dos imágenes.
¿A que ya sólo el nombre asusta? No consigo encontrar una forma no abstracta de explicaros este método, pero si recordáis la entrada anterior que os enlazaba, dedicada a la transformada de Fourier recordaréis que íbamos probando frecuencias y cuando nuestra forma de onda contenía esa frecuencia al multiplicar daba un máximo. Esto es algo parecido, vamos a coger una imagen grande y calcularemos sus frecuencias (sí, en imágenes también existen las frecuencias). Luego vamos a coger una imagen más pequeña, contenida dentro de la grande y calcularemos sus frecuencias. Multiplicamos ambas y obtenemos un resultado que… puff, ¡qué lío! Bueno, mejor verlo.
Esta es nuestra imagen grande, una sopa de letras tomada de http://listocomics.com/la-primera-sopa-de-letras-sin-vocales/, visitad la entrada, es curiosa.

Digamos que en esa sopa queremos encontrar todas las posiciones donde hay una N. Esta operación se llama Template matching y hay varias formas de hacerlo. Vamos a usar el método que explican en http://www.dspguide.com/ch24/7.htm, libro que me gusta mucho y que os recomiendo leer si os gusta el procesamiento digital de datos y sabéis inglés.
Esta va a ser nuestra plantilla, lo que queremos encontrar:
Los pasos del método son:
- Preparar las imágenes. Por ejemplo, la sopa de letras está escrita en negro sobre blanco. Digitalmente el blanco es el valor más alto (255 o 1) y el negro es el más bajo (0). Este método funciona mejor cuando usamos como fondo el valor más bajo (negro). Así que tenemos que invertir los colores. Otros preparativos son normalizar los valores entre 0 y 1 en vez de entre 0 y 255 para facilitar las operaciones.
- Rotar la plantilla 90 grados. Espacialmente es equivalente a invertir las frecuencias. No sabría explicaros sin matemáticas por qué se hace esto pero así maximizamos la correlación.
- Obtener ambas transformadas de Fourier, tanto de la muestra como de la imagen grande. Utilizaremos la función fft2 de octave.
- Multiplicar escalarmente ambas transformadas, para lo cual deben ser del mismo tamaño. Esta operación es la más importante. La transformada de la imagen completa tiene todas las frecuencias de esta, la transformada de la muestra sólo tiene las frecuencias que nos interesan. Multiplicando ambas nos quedamos con las frecuencias que están en las dos imágenes, puesto que si alguna frecuencia no existe en la muestra valdrá cero, al multiplicar se eliminará de la imagen grande y sólo quedarán las frecuencias que estén en la muestra.
- Aplicar la transformada inversa al resultado. La imagen que obtenemos es la convolución de la grande con la plantilla.
- Ajustar el umbral Blanco/Negro en el resultado para quedarnos sólo con los máximos a partir de un cierto valor. Estos máximos indican la posición de la muestra o plantilla dentro de la imagen grande.
Veámoslo gráficamente. Teníamos nuestra sopa de letras original. La normalizamos e invertimos el color para que el fondo sea negro (valor 0).
sopa = imread('sopa.png');
sopa = double(sopa);
sopa = sopa - min(min(sopa));
sopa = sopa / max(max(sopa));
sopa = 1 - sopa;

La misma operación hacemos con la N que nos servirá de muestra. Ahora hemos preparado una función en octave que llamamos convoluciona, este es el código:
function result = convoluciona (grande, peque)
grander = size(grande)(1);
grandec = size(grande)(2);
grande = double(grande);
peque = double(peque);
grande = grande / max(max(grande));
peque = peque / max(max(peque));
peque = rot90(peque,2);
grandefft = fft2(grande, grander, grandec);
pequefft = fft2(peque, grander, grandec);
conv = grandefft .* pequefft;
result = abs(ifft2(conv));
end
Observad que primero obtenemos el tamaño de la imagen grande para utilizarlos cuando hagamos la trasformada de la imagen pequeña. Si las matrices no tienen el mismo tamaño no podemos multiplicarlas. Luego pasamos las matrices a double. Imread carga las imágenes en matrices de tipo entero, sin decimales. Es un problema cuando hagamos divisiones para normalizar, así que primeramente las convertimos en matrices de coma flotante. Hacemos una normalización. Y a continuación hacemos el giro, y la convolución como hemos descrito antes.
Obtenemos este resultado:
result = convoluciona(sopa, n);
result = result / (max(max(result)));

Esta imagen borrosa no nos dice nada a simple vista. Ahora vamos a superponerla con la imagen original de la sopa de letras:

Los puntos más o menos brillantes están todos en la esquina inferior derecha de cada carácter. Es más, las zonas más brillantes corresponden a las letras que más se parecen a la muestra, N y M. Si os fijáis en letras como la C, la T o la L la esquina inferior derecha es menos brillante.
Para saber dónde hay N debemos tomar un umbral entre 0 y 255. Necesitamos un umbral en vez de un único valor máximo porque la sopa de letras está ligeramente girada, además es una página escaneada. Si a todo le sumamos que el fichero original es un JPG con distorsión repuesta que no todas las N son idénticas, y estas diferencias producen variaciones en el resultado.
Tomamos un umbral de 222, por ejemplo:

Con este umbral identificamos todas las N -fijaos que tienen un punto abajo en la esquina-. Pero también identificamos una M a la izquierda como un falso positivo. Con un umbral más alto no tendríamos ese falso positivo, pero nos habríamos dejado alguna N sin identificar (falso negativo).
Ya habéis visto cómo funciona el reconocimiento de patrones por convolución. En general, la FFT es una operación relativamente costosa pero muy optimizada. La conveniencia de usar este método u otros depende del tamaño de la imagen de muestra. Una ventaja fundamental que usaremos acto seguido es que, de una sola pasada comparamos un carácter con todos los caracteres de la imagen, sin importar su posición.
Preparación
Decíamos que de una pasada comparamos un carácter de muestra con todos caracteres que hay en una imagen. Y es justamente lo que nos viene bien ahora. Porque tenemos un carácter UTF que precisamente queremos comparar con un total de 52 caracteres (letras mayúsculas y minúsculas) para ver si se parece a alguno.
Antes hay que tomar algunas precauciones, porque hay letras que están contenidas dentro de otras, por ejemplo “I” y “l”, o que tienen acentos, cedillas, etc. para evitar que el método identifique estas letras erróneamente como iguales, vamos a comparar sólo el contorno. También es conveniente marcar el comienzo y el final de cada carácter para que dos caracteres juntos no se identifiquen como uno, por este motivo insertaremos caracteres de delimitación. También podríamos separar más los caracteres.
Así por ejemplo, para la letra “a” tenemos esta forma:

Construimos una imagen muy larga con todas las letras que nos van a servir de base para ir comparando los distintos caracteres UTF (clic para ampliar):

Fase de calibrado
Resumiendo: con el método descrito, viendo cuánto valen y dónde están los máximos podemos saber si se parece a alguna letra de las que teníamos en la imagen.
¿Y cómo asociamos un máximo en una posición, con la letra a la que pertenece? Pues una solución es calculándolo en función del ancho de cada carácter. La otra, que me gusta más, es con una primera etapa de calibración.
El razonamiento es: comparo cada una de las letras de muestra con la imagen donde están todas y miro dónde está el máximo y cuanto vale. Luego cuando tenga que comparar un carácter UTF desconocido miro en las posiciones que sabía que están los máximos. Comparando el resultado del carácter UTF incógnita con el valor obtenido en esa posición durante el calibrado sabré, cuanto más aproximados sean estos valores, si las letras se parecen o no.
Por ejemplo, buscamos la letra a en la fila de letras anterior. Este es el resultado:

Superpongamos, como antes, la imagen original (o un fragmento, que es muy larga):

Efectivamente el máximo está bajo la a. Con octave buscamos la posición y valor de cada máximo y lo guardamos en una variable. Suponiendo que previamente hemos creado las imágenes base, esta función es la que hace el calibrado:
function [val, posi, posj] = calibrar
% Convoluciona cada letra individual con la imagen de letras base,
% para ver por donde cae cada pico
% y devuelve un array de vectores con los valores de calibrado
% ceil(Maximo) , fila , columna
base = imread ('imagenes/base.png');
base = double(base);
base = base / max(max(base));
val = [];
posi = [];
posj = [];
letras = ['ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'];
for c = letras
file = sprintf("imagenes/%s.png",c);
indiv = imread(file);
indiv = double(indiv);
indiv = indiv / max(max(indiv));
result = convoluciona(base, indiv);
[i,j] = find(result == max(max(result)));
val = [val ; max(max(result)) ];
posi = [posi ; i ];
posj = [posj ; j ];
printf("%c: Max: %d, i=%d j=%d\n",c,ceil(max(max(result))),i,j);
end
Este sería el resultado: i y j representan la posición del máximo dentro de la imagen. El máximo depende de cuántos píxeles tenga la muestra y sus valores.
Calibrando...
A: Max: 4692, i=178 j=205
B: Max: 5530, i=178 j=450
C: Max: 4849, i=178 j=706
D: Max: 5010, i=178 j=962
E: Max: 4942, i=178 j=1207
F: Max: 4115, i=178 j=1441
G: Max: 5772, i=178 j=1709
H: Max: 4747, i=178 j=1965
...
a: Max: 4507, i=178 j=6613
b: Max: 4600, i=178 j=6836
c: Max: 3775, i=178 j=7048
d: Max: 4668, i=178 j=7271
e: Max: 4438, i=178 j=7494
...
Fase de comparación
A partir de aquí el proceso es un bucle:
- Tomar el siguiente carácter UTF.
- Generar una imagen con él -con su contorno-.
- Aplicar convolución.
- Anotar los valores que toma en la posición donde antes estaban los máximos.
Y repetir hasta el carácter UTF que hayamos puesto de máximo. Al buscar en bloques UTF muy altos tened en cuenta que algunas tipografías están incompletas y no los incorporan. Las imágenes las generamos con ImageMagick, y utilizamos Perl como pegamento para unirlo todo.
Con los resultados obtenidos componemos una tabla en sqlite. La creación de la base de datos es un proceso muy costoso y puede ser largo, pero sólo hay que hacerlo una vez. Tened en cuenta que esta tabla será específica para la tipografía que estemos usando. Si bien en este aspecto no hay mucha diferencia entre las tipografías más usuales.
¿Cómo funciona el script? Pues vamos a crear una base de datos para la fuente FreeSans comparando sólo el carácter UTF-1089. Porque todos los números son interesantes, incluso el 1089.
Recordad que primero se hace una calibración para establecer la posición de los máximos.
$ ./creaDB 1089 1089
Creando imagen con los caracteres base...
Creando letras individuales: ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
Creando letras que compararemos: с
Comparando (esto puede tardar)
Calibrando...
A: Max: 4692, i=178 j=205
B: Max: 5530, i=178 j=450
C: Max: 4849, i=178 j=706
...
a: Max: 4507, i=178 j=6613
b: Max: 4600, i=178 j=6836
c: Max: 3775, i=178 j=7048
d: Max: 4668, i=178 j=7271
...
x: Max: 3830, i=178 j=11421
y: Max: 3974, i=192 j=11633
z: Max: 3856, i=178 j=11845
Vale, comparando...
Comparando el caracter 1089...
lim_i = 192
lim_j = 11845
k=1, posi=178, posj=205, i=176:180, j=202:208, semejanza=0.121922
k=2, posi=178, posj=450, i=176:180, j=445:455, semejanza=0.113667
k=3, posi=178, posj=706, i=176:180, j=698:714, semejanza=0.110823
...
k=27, posi=178, posj=6613, i=176:180, j=6546:6680, semejanza=0.491005
k=28, posi=178, posj=6836, i=176:180, j=6767:6905, semejanza=0.561705
k=29, posi=178, posj=7048, i=176:180, j=6977:7119, semejanza=0.905537
k=30, posi=178, posj=7271, i=176:180, j=7198:7344, semejanza=0.578346
...
k=50, posi=178, posj=11421, i=176:180, j=11306:11536, semejanza=0.349784
k=51, posi=192, posj=11633, i=190:192, j=11516:11750, semejanza=0.152881
k=52, posi=178, posj=11845, i=176:180, j=11726:11845, semejanza=0.350682
Insertando el resultado en la base de datos...
Tabla FreeSans creada correctamente.
Pulsa una tecla para eliminar las imagenes temporales.
Hecho.
Parece que el carácter UTF-1089 tiene una semejanza bastante alta con el carácter que se encuentra en la posición k=29. Eso es una c minúscula. Hay una semejanza de 0.9, relativamente alta comparada con el resto de caracteres.
En realidad se trata de la ‘s’ cirílica. Gráficamente es cierto que se parece muchísimo a una c, aunque es ligeramente más estrecho y por eso la semejanza no llega al 100%. Mirad la comparación de ambos caracteres:

El desplazamiento hace que el máximo no esté donde esperamos. Durante el calibrado el máximo de la c estaba en la posición (h=178, l=7048) y valía 3774.8:
Calib c: 178, 7048 = 3774,8
Si miramos esa misma posición tras la convolución con UTF-1089 obtenemos el valor 2448.8. La semejanza será de un escaso 60% si nos fiamos de esto. Por eso el proceso tiene un margen de tolerancia que busca el máximo en un entorno de unos 20 píxeles a la redonda de donde lo espera. En este caso el máximo está en la posición (h=178, l=7051) y vale 3418.3. De ahí obtenemos el 90% de semejanza.
Aplicación
Y ahora que ya tenemos nuestra base de datos de semejanzas construída ¿qué hacemos? Pues, naturalmente, emplear los símbolos que hemos encontrado para componer palabras.
Por ejemplo, la palabra ‘ciencia’ se compone de los caracteres
c i e n c i a
99 105 101 110 99 105 97
y con ayuda de un script vamos a buscar combinaciones de la palabra ‘ciencia’ que contengan carácteres extraños pero muy parecidos a estos.
$ ./creafrase
Dime una palabra: ciencia
Pido semejanza de c_min.
Pido semejanza de i_min.
Pido semejanza de e_min.
Pido semejanza de n_min.
Pido semejanza de c_min.
Pido semejanza de i_min.
Pido semejanza de a_min.
Hay 2096 combinaciones. Quieres cuantas...
Introduce un numero entre 1 y 2096: 25
Creando las combinaciones encontradas:
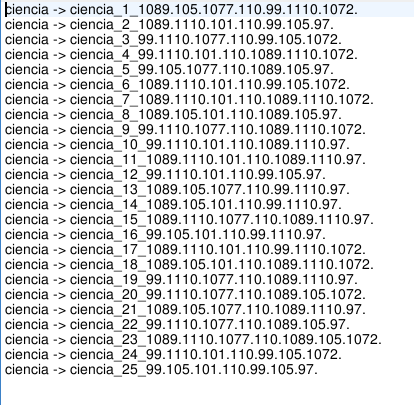
ciencia_1_1089.105.1077.110.99.1110.1072.
ciencia_2_1089.1110.101.110.99.105.97.
ciencia_3_99.1110.1077.110.99.105.1072.
ciencia_4_99.1110.101.110.1089.1110.1072.
ciencia_5_99.105.1077.110.1089.105.97.
ciencia_6_1089.1110.101.110.99.105.1072.
ciencia_7_1089.1110.101.110.1089.1110.1072.
ciencia_8_1089.105.101.110.1089.105.97.
ciencia_9_99.1110.1077.110.1089.1110.1072.
ciencia_10_99.1110.101.110.1089.1110.97.
ciencia_11_1089.1110.101.110.1089.1110.97.
ciencia_12_99.1110.101.110.99.105.97.
ciencia_13_1089.105.1077.110.99.1110.97.
ciencia_14_1089.105.101.110.99.1110.97.
ciencia_15_1089.1110.1077.110.1089.1110.97.
ciencia_16_99.105.101.110.99.1110.97.
ciencia_17_1089.1110.101.110.99.1110.1072.
ciencia_18_1089.105.101.110.1089.1110.1072.
ciencia_19_99.1110.1077.110.1089.1110.97.
ciencia_20_99.1110.1077.110.1089.105.1072.
ciencia_21_1089.105.1077.110.1089.1110.97.
ciencia_22_99.1110.1077.110.1089.105.97.
ciencia_23_1089.1110.1077.110.1089.105.1072.
ciencia_24_99.1110.101.110.99.105.1072.
ciencia_25_99.105.101.110.99.105.97.
Pulsa una tecla para eliminar las imagenes temporales.
Hecho.
Este script nos genera un fichero de salida con las primeras 25 combinaciones que haya encontrado. Abramos el fichero con gVim, por ejemplo, que utiliza una tipografía distinta a la que hemos usado para confeccionar la tabla, donde se diferencian los caracteres UTF superiores.
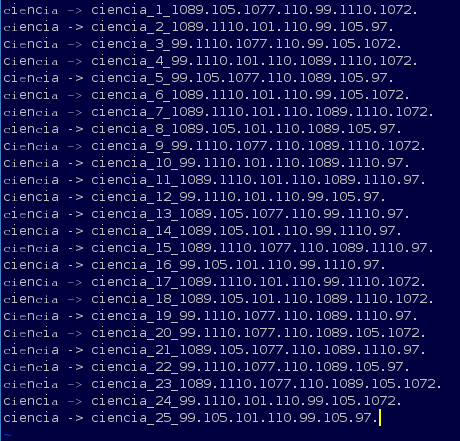
La primera columna en la palabra escrita de manera alternativa, se ve claramente distinta a la misma palabra escrita a la derecha con letras latinas. Fijaos que el script nos propone alternativas para la letra c, la i, la e y la a. En concreto las sustituye por caracteres similares del bloque cirílico, presente en la mayoría de tipos que soportan UTF.
Si en el gVim se puede distinguir una palaba de sus homógrafas es porque he configurado una tipografía diferente, en otras aplicaciones como kwrite resulta mucho más complicado:
¿Cómo se ve en tu navegador? Vamos a hacer la prueba; tal vez se vean iguales o tal vez no, depende de la configuración de tu sistema.
¿Puedes distinguir la ciencia de las pseudociencias?
сiеncіа сіencia cіеnciа
cіenсіа ciеnсia сіenciа
сіenсіа сienсia cіеnсіа
cіenсіa сіenсіa cіencia
сiеncіa ciencia сiencіa
сіеnсіa ciencіa сіencіа
сienсіа cіеnсіa cіеnсiа
сiеnсіa cіеnсia сіеnсiа
Comprúebalo copiando y pegando. Cuando buscas en google una homógrafa, aunque se vea idéntica y se lea igual son palabras distintas (acordaos de activar el modo verbatim de google para que no os muestre palabras semejantes o relacionadas):
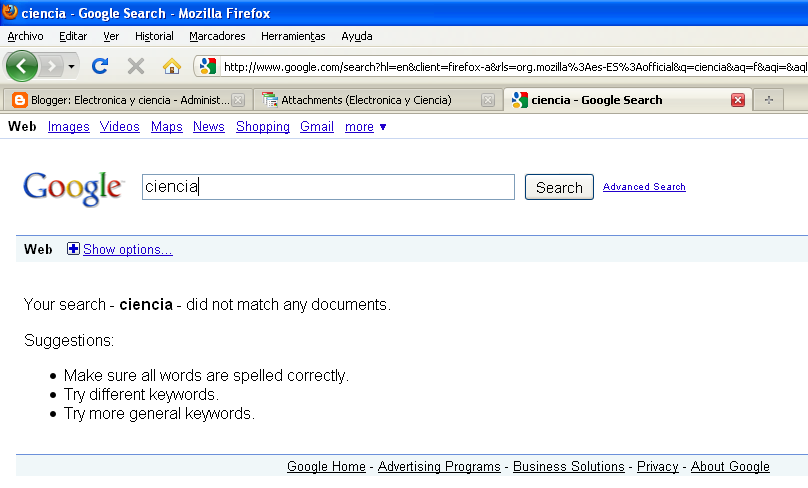
No encuentra nada porque la captura de pantalla la he hecho antes de publicar este artículo. En cuando google lo incorpore, si buscas una homógrafa de ciencia supongo que te aparecerá este mismo artículo.
Aplicaciones
¿Y qué se puede hacer con esto? Pues una respuesta rápida podría ser marcado de textos. Si cambio todas las c del artículo, por c en cirílico, una simple búsqueda en google me permitiría averiguar qué páginas han copiado o plagiado parte del texto. Es una marca de agua muy sencilla de eliminar, pero sólo si sabes que está ahí. Y, como hemos visto, no es fácil darse cuenta del engaño.
¿He dicho engaño? Cada vez más se popularizan los dominios con caracteres UTF, dominios internacionalizados o IDN, que permiten poner direcciones web con caracteres griegos o cirílicos. Muchos navegadores, por seguridad, muestran en la barra de direcciones el dominios traducido al que realmente nos dirigimos. Si visitamos con Firefox la web http://www.españa.com nos mostrará que, realmente, esto es http://xn–espaa-rta.com/.
Alguien malintencionado podría tener la idea de registrar un dominio falso por ejemplo http://bаnkinter.com y utilizarlo para robar credenciales de acceso y tarjetas de crédito por medio de un sencillo phishing. En general, los navegadores son conscientes de este problema; por ejemplo la política de Opera al respecto es tener una lista blanca:
Opera has added a whitelist of top-level domains that are trusted to enforce a safe policy on domain names. Several top-level registrars have strict rules for domain names. Opera for Windows, Mac and UNIX will check for an updated list of trusted TLDs on a regular basis. Opera now only accepts Latin 1 characters in domain names from top-level domains that are not on the whitelist. This covers Western European languages without introducing any convincing homographs.
Otros navegadores, por comodidad permiten al usuario decidir si prefiere ver el dominio en UTF o el dominio real traducido en la barra de direcciones. Lo primero podría ser una imprudencia.
No me consta que sea un ataque muy difundido a día de hoy, pero es una amenaza y podría ser un problema de seguridad en el futuro.
Como siempre os dejo el código, una base de datos para pruebas, algunas imágenes y ejemplos en este enlace.