 Electronica y Ciencia
Electronica y CienciaRegistrador de ruido ambiental
- Entrada de micrófono
- Supresión de ruido
- Monitor de sonido
- Envío a InfluxDB Cloud
- Paneles en Grafana
- Indicador de últimos 30 minutos
- Tipos de sonidos
- Eventos periódicos
- Conclusión y enlaces
Hoy vamos a hacer un sencillo Registrador de Ruido Ambiente. En la primera mitad del artículo usaremos un micrófono y una Raspberry Pi para programarlo con Python y SoX. En la segunda, enviaremos los resultados a InfluxDB Cloud y mostraremos los intervalos de ruido o silencio en Grafana mediante consultas Flux.
La idea principal es un programa que esté continuamente recogiendo audio. Calcule el RMS cada 5 segundos y lo escriba por la salida estándar. Después cargarlo en una base de datos y dibujar gráficas. En sí es sencillo y sólo requiere unas pocas líneas de código, pero hay algunos puntos interesantes que seguramente puedas reutilizar en otros proyectos. Tal como:
- utilizar SoX para obtener y eliminar un perfil de ruido
- leer un stream binario en Python
- conocer el valor eficaz y cómo se relaciona con la forma de onda
- enviar datos a InfluxDB Cloud v2.0 con Curl llamando directamente al API
- usar Bash para monitorizar un fichero y ejecutar un comando por cada línea nueva
- hacer consultas complejas con Flux
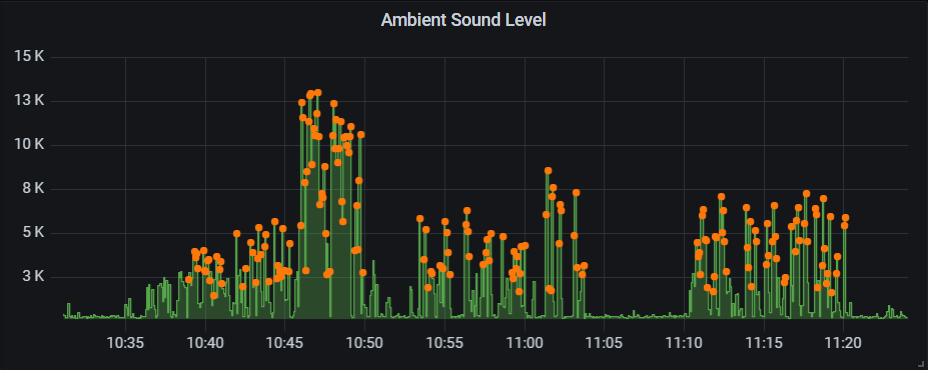
Gráfico del ruido ambiental una mañana con los vecinos de obras. EyC.
Entrada de micrófono
La Raspberry Pi -al menos la versión 3- no tiene entrada de audio. Tiene un Jack, sí, pero es sólo salida. Para conectar un micrófono y registrar audio es preciso conectar una tarjeta de sonido. Las hay USB por menos de un dólar. Son de mala calidad, por supuesto, pero suficiente. Hace tiempo modificamos una para Medir valores lógicos con tarjeta de sonido.

Tarjeta de sonido USB. Aliexpress.
Cuenta con un chip TP6911 (bien en chip o en gota) y varios componentes pasivos. Aunque menos de los que debería.
Una vez enchufada, Raspbian la reconoce automáticamente:
$ lsusb
Bus 001 Device 006: ID 1130:f211 Tenx Technology, Inc. TP6911 Audio Headset
Bus 001 Device 003: ID 0424:ec00 Standard Microsystems Corp. SMSC9512/9514 Fast Ethernet Adapter
Bus 001 Device 002: ID 0424:9514 Standard Microsystems Corp.
Bus 001 Device 001: ID 1d6b:0002 Linux Foundation 2.0 root hub
Como hemos dicho, la Raspberry ya integra un dispositivo de audio. Pero sólo permite reproducir, no grabar. Por esa razón nos mostrará dos tarjetas cuando las listemos con aplay -l. Si queremos ver los dispositivos de grabación debemos hacerlo con arecord -l. La tarjeta 1 (USB AUDIO) es la única que aparece:
$ arecord -l
**** List of CAPTURE Hardware Devices ****
card 1: AUDIO [USB AUDIO], device 0: USB Audio [USB Audio]
Subdevices: 0/1
Subdevice #0: subdevice #0
El paquete SoX es un software de procesamiento de audio en línea de comandos. Sirve para grabar, aplicar algunos filtros y volcar las muestras en el formato necesario. La línea de comandos de sox siempre tiene la misma forma:
sox <opciones_archivo_entrada> <archivo_entrada> <opciones_archivo_salida> <archivo_salida> <filtros y efectos>
Los archivos de entrada y salida pueden ser ficheros de disco, dispositivos físicos, la entrada y salida estándar o ninguno.
En este caso el fichero de entrada es hw:1 (card 1) de tipo alsa con los parámetros por defecto y la salida será a /tmp/output.wav. Como termina en wav SoX ya identifica el tipo por la extensión. Y si no indicamos los parámetros de salida tomará los mismos que de entrada. O sea los valores por defecto del TP6911: un canal (mono) a 16 bit y a 24kHz.
$ sox -t alsa hw:1 /tmp/output.wav
Input File : 'hw:1' (alsa)
Channels : 1
Sample Rate : 24000
Precision : 16-bit
Sample Encoding: 16-bit Signed Integer PCM
Grabamos unos segundos hablando al micro y lo abrimos con audacity. El resultado no es bueno:
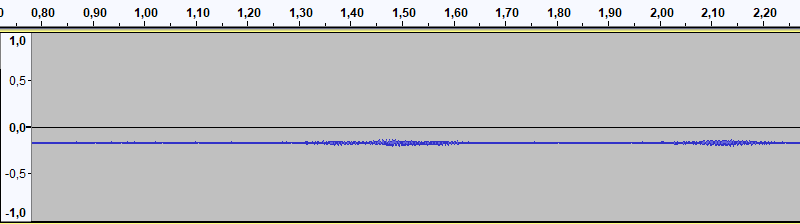
Primera prueba de sonido con tarjeta USB y micro electret. EyC.
Extraño que la pista no esté centrada en 0. Puede pasar por un defecto en el hardware. El filtro stat nos muestra entre otros valores la media aritmética de las muestras.
$ sox -t alsa hw:1 -n stat
Maximum amplitude: -0.066406
Minimum amplitude: -0.480469
Mean amplitude: -0.170199
Efectivamente está desplazado -0.170199. Las unidades ahora no importan. Por cierto, el fichero de salida aquí es -n, es decir, ninguno. Porque lo que nos interesa es sólo la estadística.
Se soluciona bloqueando la componente continua con un filtro paso alto. SoX tiene un filtro que sirve justo para corregir desplazamientos y se llama dcshift. Pero un filtro es más versátil.
Una vez centrado, amplificamos para ver la relación señal-ruido:
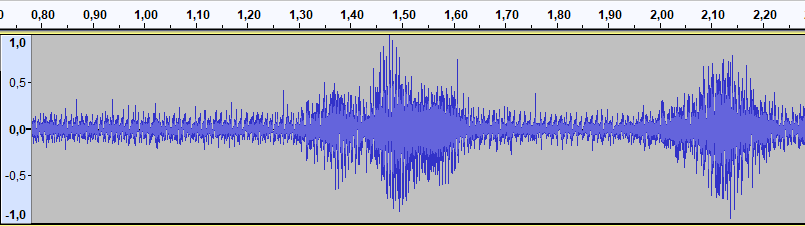
Comparación entre la señal útil y el ruido de fondo. EyC.
Horrible. ¿Qué esperabas con una tarjeta de sonido de un euro y un micro electret?
Supresión de ruido
Había escrito unos párrafos hablando sobre las fuentes del ruido eléctrico. Pero no veas qué tostón me estaba quedando. Resumiendo: filtros insuficientes (o ninguno), alimentación no desacoplada, componentes baratos y partes importantes sin blindar. Además recuerda que, sin filtros, las señales de alta frecuencia acaban plegadas por aliasing en cualquier frecuencia audible.
Si queremos captar el ruido de la habitación, lo primero será eliminar el de la línea. Como es un murmullo de fondo más o menos continuo se puede hacer un perfil de frecuencias y luego filtrarlo. Lo malo es que la señal buena se distorsionará. Pero en este caso nos da igual la fidelidad. Son ruidos, sólo buscamos su volumen.
Crearemos un perfil grabando un segundo de “silencio” con SoX.
sox -t alsa hw:1 -r 8000 -b 16 -c 1 -n trim 0 1 highpass 20 noiseprof noise.prof
Es decir:
- el fichero de entrada es tipo ALSA,
hw:1con los parámetros por defecto. - Fichero de salida
-n(ningún fichero) a 8kHz, 16 bits, mono. - Cortamos la grabación entre los tiempos 0 y 1s (
trim 0 1). - Aplicaremos
highpass-como explicamos antes- para centrar la onda. - Finalmente aplicamos el filtro
noiseprofy guardamos el resultado en noise.prof.
Ojo, las operaciones de I/O y el consumo del procesador también meten ruido. Por eso el perfil puede ser distinto si primero grabas a un fichero y acto seguido obtienes el perfil de lo grabado.
El filtro noisered es complementario de noiseprof. Sirve para filtrar con un perfil guardado. Lleva un parámetro para seleccionar la intensidad. El resultado está tan distorsionado que recuerda a una psicofonía pero, eso sí, limpio.
sox ... highpass 20 noisered noise.prof 0.3 gain 30
Finalmente, amplificamos la señal con gain dependiendo de la sensibilidad que queramos. Es importante centrar primero, limpiar, y luego amplificar. De hacerlo al revés estaríamos multiplicando la desviación y sólo conseguiríamos desplazar aún más la onda y saturar el extremo negativo.
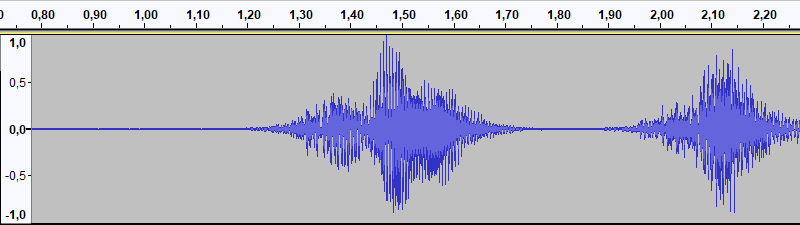
La misma señal anterior una vez filtrado el ruido. EyC.
Monitor de sonido
Ya sabemos captar audio en la Raspberry, acondicionarlo y filtrarlo. Ahora describiremos el programa principal.
SoX puede volcar las muestras a la salida estándar (fichero de nombre -). A razón del Sample Rate seleccionado. Y lo hace en dos formatos principalmente.
Formato dat o sea, texto. Donde la primera columna es el tiempo y la segunda el valor decimal entre -1 y 1.
$ sox hola.wav -t dat -
; Sample Rate 8000
; Channels 1
0 -0.098083496
0.000125 -0.17147827
0.00025 -0.14813232
0.000375 -0.15866089
Formato raw o sea binario. En este caso enteros de 16 bit con signo.
$ sox hola.wav -t raw - | hexdump | head
0000000 f372 ea0d ed0a ebb1 ebf9 ec02 ecde eb1e
0000010 ec09 eb5f eaf7 ebb9 ec50 eb19 eb01 eae4
0000020 ea8a eaf3 ea72 ea7e eae9 ea99 ea95 ea40
La información es la misma en ambos. Mira por ejemplo la primera muestra. En el ejemplo binario es 0xf372. Interpretado como signed integer vale -3214. Dividido entre 32768 que es el valor máximo absoluto nos da -0.09808; justo la primera muestra del formato texto.
El formato texto es práctico para leerlos con cualquier software como si fuera un CSV. Pero tiene mayor coste de CPU ya que SoX debe convertir los enteros a flotante y nuestro programa hacer la operación inversa. Además la columna de tiempos no nos hace falta porque el procesamiento es en tiempo real. Por si fuera poco, presenta el inconveniente de que SoX usa notación científica y puedes encontrarte cosas como:
0.040125 0.0039112843
0.04025 4.1758642e-05
0.040375 0.0051604784
Dicho de otra forma, el formato binario es más fácil de procesar para la máquina pero más difícil para nosotros.
El objetivo es averiguar en qué momento del día se recogen sonidos altos. Grabar continuamente todo el tiempo se volvería inmanejable. Así que lo haremos a intervalos de 5 segundos. En un día serían unos 17000 registros. A 40 caracteres por línea da unos 650kb al día. Más razonable.
Es decir, estaremos grabando continuamente. Pero en lugar de volcar todas las muestras a disco, las recogeremos con nuestro programa. Y cada 5 segundos escribiremos el valor máximo y el RMS durante dicho intervalo.
Ejecutando SoX como un subproceso podremos leer su salida en nuestro bucle principal. En Python sería algo así (GitHub electronicayciencia - sndobras/sndobras.py):
cmdline = "sox -t alsa hw:1 -r 8000 -t raw - highpass 20 noisered noise.prof 0.3 gain 32"
proc = Popen(cmdline, shell=True, stdin=PIPE, stdout=PIPE)
while True:
twobytes = proc.stdout.read(2)
i = int.from_bytes(twobytes, byteorder='little', signed=True)
nsamples = nsamples + 1
sumsq = sumsq + i*i
maxvalue = max(abs(i), maxvalue)
Para SoX, su fichero de salida es -, o sea stdout. Ahorraremos tiempo de procesador reduciendo de 24000 a 8000 muestras por segundo. Aunque la frecuencia de muestreo del TP6911 es de 24kHz y no se puede cambiar, al especificar la opción -r 8000 SoX hará el resampling.
Durante el bucle principal contaremos del número de muestras, el máximo y la suma de los cuadrados. Cada intervalo de 5 segundos a 8kHz, tiene 40000 muestras.
Ejecutamos el monitor y vamos guardando los resultados en un archivo:
$ ./sndobras.py >> ruido.log
La salida de sndobras.py es una tabla con cuatro columnas: fecha en formato legible, timestamp, valor eficaz (RMS) y valor máximo.
2021/04/13-21:25:17 1618341917 1212 14564
2021/04/13-21:25:22 1618341922 538 11916
2021/04/13-21:25:27 1618341927 441 6736
2021/04/13-21:25:32 1618341932 607 11663
Mira estas dos grabaciones, una es un golpe seco y la otra un silbido.
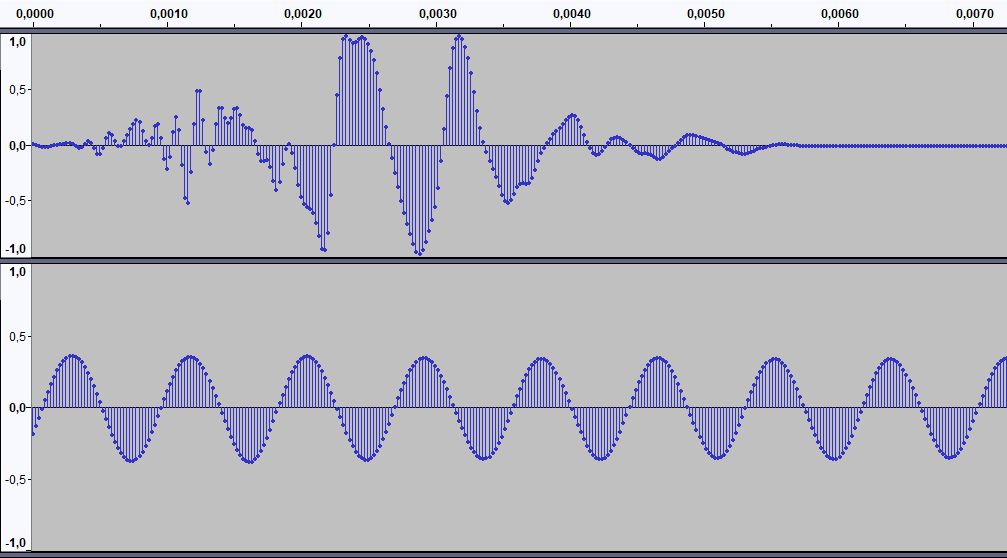
Juntos, los valores máximo y eficaz nos dan una idea del tipo de sonido. EyC.
El RMS o valor eficaz es simplemente una media cuadrática. Digamos que es proporcional al área coloreada. En la pista superior el valor máximo es tope. No puede pasar de ahí. Pero debido a su brevedad el valor eficaz será relativamente pequeño. En el ejemplo inferior, con un máximo más discreto, el RMS será mayor porque se prolonga en el tiempo.
¿Podríamos decir que el máximo es la amplitud y el RMS una combinación de amplitud y duración?
Además es formalmente correcto. Aquí tienes una tabla de conversión de valor eficaz. De las que venían antes con los tester.
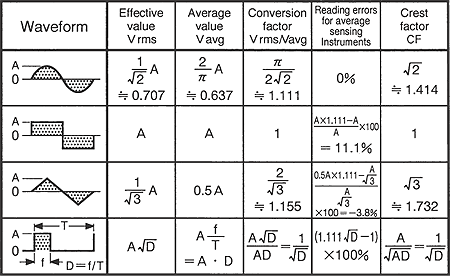
Tabla de un tester TrueRMS. KYORITSU
En el primer caso es todo el intervalo lleno con una sinusoidal de amplitud A. El valor eficaz será 0.7 veces A. Da igual la frecuencia. En nuestro caso, con muestras de 16 bits el máximo es 32768; resultaría un RMS de 23000 más o menos.
Si aumentamos el volumen la onda se saturará y la sinusoidal se volverá cuadrada. Estaríamos en el segundo caso: el máximo RMS daría el mayor valor posible, o sea los 32768. Tendría que ser un sonido fuerte que durara todo el intervalo de 5 segundos.
Con una onda arbitraria, tendríamos el tercer caso: el RMS depende de la forma de onda.
Y si es un ruido intenso pero breve estaríamos en el cuarto caso: el RMS vendrá en función de la duración relativa del sonido e intervalo.
Envío a InfluxDB Cloud
InfluxDB es una base de datos especialmente pensada para trabajar con series temporales. Aún no he tenido ocasión de trabajar con ella y este proyecto me servirá como primer contacto.
A día de hoy (2021) conviven dos versiones:
- v1.8.x. Que se organiza sobre concepto de database. Su lenguaje de consulta es InfluxQL y está bien soportado en Grafana.
- v2.0. Nueva. Trabaja con organization y bucket. Se consulta con otro lenguaje, Flux, cuyo soporte en Grafana no es tan bueno.
Se puede instalar fácilmente en una Raspberry. Pero probaré la versión Cloud. Gratuita. Ofrecen 30 días de persistencia de datos. Servirá. Eso sí, es InfluxDB v2.
Hay múltiples herramientas para recolectar datos y enviarlos InfluxDB. Pero este caso es lo bastante simple como para hacerlo llamando directamente al API REST.
Como es la versión 2, se necesita el bucket y la organización. La autorización se hace por medio de un token que habremos creado previamente con permisos de escritura sobre dicho bucket.
curl "$URL/api/v2/write?bucket=$BUCKET&org=$ORG" \
-H "Authorization: Token $TOKEN" \
-H 'Content-Type: text/plain' \
--data "$lineformat"
El formato de datos se llama Line protocol y tiene el siguiente aspecto:
nombreserie[,tag1=a,tag2=b,...] campo1=valor1[,campo2=valor2,...] timestamp
Al nombre de la serie lo llaman measurement. Puedes poner lo que quieras. Los tags son opcionales y sirven para filtrar. Puede haber tantos campos como sea necesario. Y el timestamp -si no se indica nada- va en nanosegundos. Más información en Line protocol.
¿Ahora dónde ponemos esta llamada?
Por un lado tienes una operación síncrona. Un ADC generando 8000 muestras por segundo sin parar que debes procesar en el momento para hacer unos cálculos y presentar resultados cada 5 segundos. Por otro, una llamada asíncrona a un API en la nube, que hoy puede ir rápido, o lento; y mañana igual se cae.
Lo mejor es crear hilos o procesos independientes y comunicarlos usando un buffer. Se puede hacer de forma muy sencilla con un script de Bash.
Aprovecharemos el fichero de salida como buffer e histórico de datos. Lo monitorizamos con tail -f y por cada línea nueva ejecutamos el curl. El script completo está en
GitHub electronicayciencia - sndobras/infuxlogger.sh.
tail -f $FILE | while read time timestamp rms maxvalue
do
lineformat="sndobras rms=$rms,maxvalue=$maxvalue ${timestamp}000000000"
curl -sS "$URL/api/v2/write?bucket=$BUCKET&org=$ORG" \
-H "Authorization: Token $TOKEN" \
-H 'Content-Type: text/plain' \
--data "$lineformat"
done
El tail -f va acoplado a un while que ejecuta lo siguiente:
readdivide en campos la línea recibida y los mete en cuatro variables- construimos el formato Line protocol. La serie se llamará sndobras. Las medidas de RMS serán rms y las de amplitud máxima maxvalue.
- llamamos al API. La opción
-sSomitirá cualquier mensaje que no sea un error.
Para cuando se efectúa la llamada, los datos ya están escritos en el fichero. Por tanto si falla o se cae la conexión esas líneas no se pierden.
Paneles en Grafana
Encuentro algo limitada la herramienta de visualización que incorpora InfluxDB Cloud. Empezando porque carece de autorefresco, ni se actualiza el intervalo temporal al seleccionar en uno de los paneles. Posiblemente no haya dado con la tecla. En cualquier caso vamos a Grafana.
Grafana se puede instalar también en la Raspberry. Pero -al igual que InfluxDB- ofrece una cuenta gratuita online. La probaremos.
Nos damos de alta, seleccionamos como fuente de datos InfluxDB. La autenticación también se hace con un token. Este debe tener permisos de lectura sobre el bucket en vez de escritura.
Hasta aquí la parte fácil. Lo complicado viene ahora. Porque Grafana (al menos hasta la versión actual v7.5.4) no tiene un asistente para escribir las consultas en lenguaje Flux. Y no sabemos Flux.
Según sus creadores, Flux -o fluxlang- es un lenguaje especialmente pensado para consultar series temporales. Su sintaxis recuerda en parte a JavaScript y en parte a pipes. Está bien documentado aunque en continuo desarrollo: Get started with Flux.
Viene de ejemplo una query básica para Grafana:
from(bucket: "testing")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "sndobras" and r._field == "rms")
|> aggregateWindow(every: v.windowPeriod, fn: mean)
- Leer de un bucket llamado testing
- filtrar el resultado por rango temporal
- filtrar el resultado por la serie y la medida que queramos
- agrupar los datos en ventanas de cierto intervalo usando la media
Empezamos por visualizar el RMS y el máximo en dos paneles uno debajo del otro. Para ver mejor cuándo sucede un pico agruparemos por max en lugar de por mean.
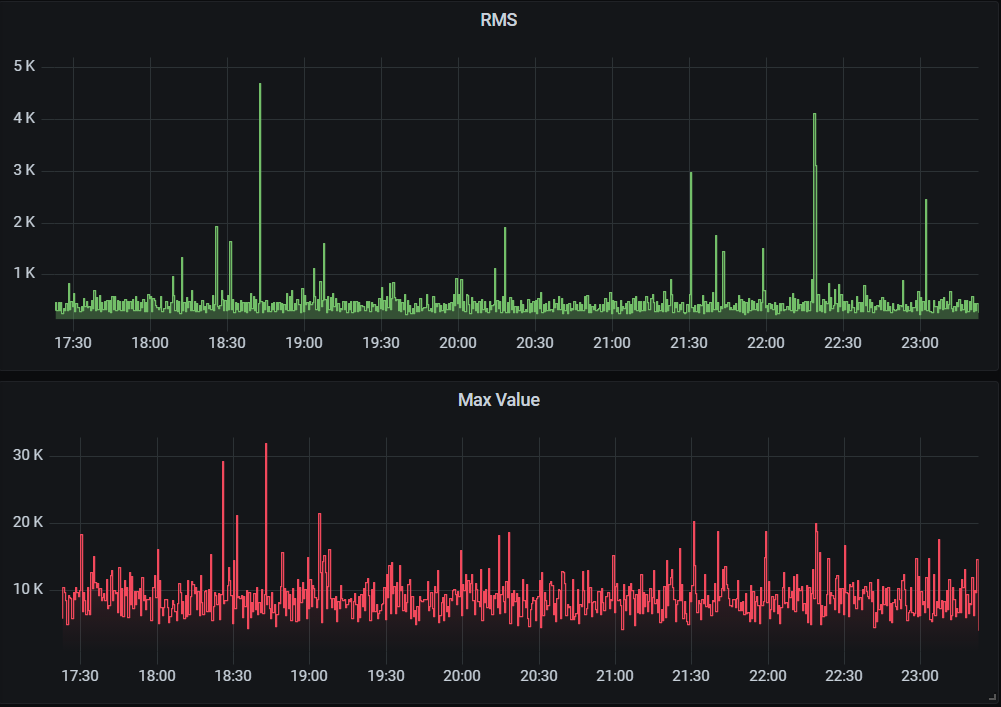
Series de RMS (arriba) y máximo de la amplitud (abajo). EyC.
En el panel del RMS (verde) me gustaría destacar de alguna manera cuándo coincide con un pico de amplitud (panel rojo). Tendríamos que crear una serie nueva quedándonos con los valores RMS para cuyos tiempos el maxvalue supera cierto umbral.
Aquí la cosa se complica. Vamos paso por paso.
Partimos de una query parecida a la anterior. Solo que esta vez debemos trabajar a la vez con rms y con maxvalue.
from(bucket: "testing")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "sndobras")
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
Nos devuelve una tabla tal que así:
_time _measurement _field _value
1619604390000 sndobras rms 461
1619604420000 sndobras rms 355
1619604450000 sndobras rms 1040
1619604500000 sndobras rms 3120
...
1619604390000 sndobras maxvalue 8698
1619604420000 sndobras maxvalue 9837
1619604450000 sndobras maxvalue 30091
1619604500000 sndobras maxvalue 32767
...
Hay que reorganizar los datos de forma que tengamos en la misma fila una columna rms y otra maxvalue. Para esto sirve la función pivot().
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
La clave de filas es _time, la clave de las columnas es _field y el valor de esa columna vendrá dado por _value. Nos queda una tabla así:
_time _measurement maxvalue rms
1619604390000 sndobras 8698 461
1619604420000 sndobras 9837 355
1619604450000 sndobras 30091 1040
1619604500000 sndobras 32767 3120
Ahora nos quedamos con aquellas filas cuya columna maxvalue es superior a 30000.
|> filter(fn: (r) => r.maxvalue > 30000)
Obtenemos las filas más interesantes:
_time _measurement maxvalue rms
1619604450000 sndobras 30091 1040
1619604500000 sndobras 32767 3120
El panel de Grafana espera el nombre de la serie en _field y su valor en _value. Como es nueva le pondremos un nombre, por ejemplo points. La función map() sirve para asignar valores a columnas.
|> map(fn: (r) => ({ r with _value: r.rms, _field: "points" }))
El resultado es una tabla con dos columnas más:
_time _measurement maxvalue rms _field _value
1619604450000 sndobras 30091 1040 points 1040
1619604500000 sndobras 32767 3120 points 3120
De las cuales sólo necesitamos tres: _field _time y _value. Así que seleccionamos esas y el resto las descartamos usando la función keep():
|> keep(columns:["_field", "_time", "_value"])
Y esta la tabla resultante: sólo las medidas de rms cuyo valor de amplitud ha superado los 30000.
_time _field _value
1619604450000 points 1040
1619604500000 points 3120
Aquí la query completa:
from(bucket: "testing")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "sndobras")
|> aggregateWindow(every: v.windowPeriod, fn: max, createEmpty: false)
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
|> filter(fn: (r) => r.maxvalue > 30000)
|> map(fn: (r) => ({ r with _value: r.rms, _field: "points" }))
|> keep(columns:["_field", "_time", "_value"])
Basta con unos retoques para hacer destacar la serie points en el panel de Grafana:
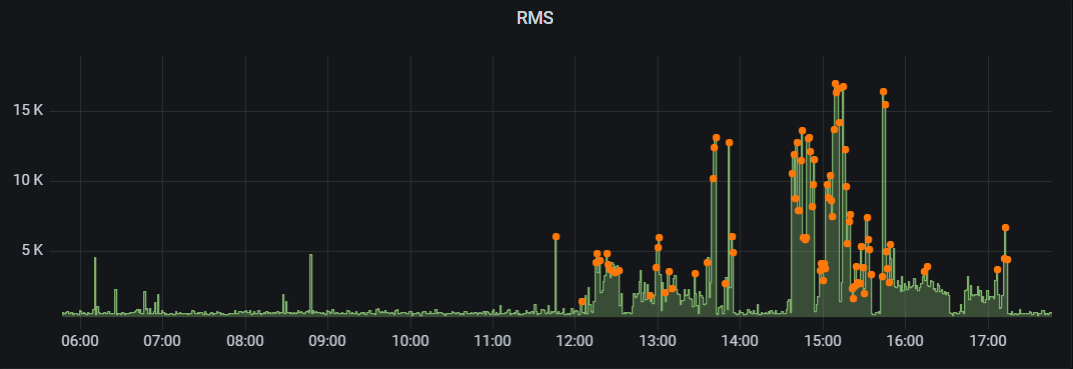
Los momentos de máxima amplitud se resaltan con puntos naranjas sobre la serie RMS. EyC.
Flux es un lenguaje interesante. Según sus autores, llevamos muchos años acostumbrados a SQL y el cambio de mentalidad es costoso. Su sintaxis aún me resulta un poco confusa. Pero la combinación de funciones con un operador pipe es ingeniosa. Atractiva incluso, para quienes estamos acostumbrados a escribir en línea de comandos cosas como:
$ cat fichero.txt | cut -d ':' -f 1 | sort | uniq -c | sort -rn | head ...
Indicador de últimos 30 minutos
Vamos con otro ejemplo. Un gauge que muestre el valor medio del RMS los últimos 30 minutos. Pero del rango seleccionado, no los 30 últimos minutos de datos. Servirá para saber si ese intervalo de tiempo lo podemos considerar tranquilo o ruidoso.
Seleccionamos los datos desde v.timeRangeStop menos 30 minutos a v.timeRangeStop. Y hacemos la media de todo.
Lo malo es que Flux trabaja o bien con timestamp o con duraciones, pero no entiende aún operaciones mixtas. No es posible especificar como tiempo de partida v.timeRangeStop - 30m. Debemos hacer la resta “fuera” de la query. Con una función que se llama experimental.subDuration().
import "experimental"
starttime = experimental.subDuration(
d: 30m,
from: v.timeRangeStop
)
from(bucket: v.bucket)
|> range(start: starttime, stop: v.timeRangeStop)
|> filter(fn: (r) => r["_measurement"] == "sndobras")
|> filter(fn: (r) => r["_field"] == "rms")
|> mean()
El resultado lo asignamos a la variable starttime y es la que usamos al filtrar con range. Una vez hecho eso, la query es sencilla y la terminamos con mean().
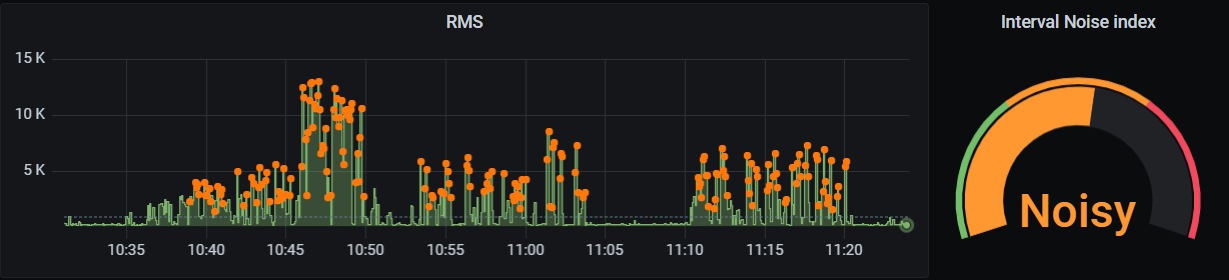
Indicador de nivel de ruido ambiental. EyC.
Tipos de sonidos
Jugando con los datos se reconocen varios patrones. Para empezar tenemos crestas periódicas del RMS cada minuto:
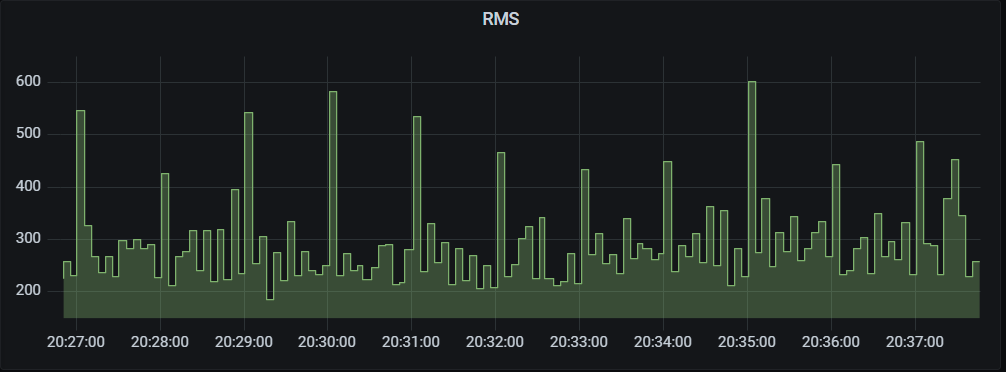
Ruido debido a un proceso periódico. EyC.
Son muy leves. No llegan a notarse en la amplitud. Se deben a un proceso cron que tengo puesto en la Raspberry, precisamente, cada minuto. Ya sabes, I/O de la memoria o un aumento del consumo de la CPU. Provocan alteraciones de microvoltios que se filtran por la alimentación hasta el micrófono y el ADC de la tarjeta de sonido. Luego se amplifican y ya vemos el resultado.
Otros eventos son picos de sonido de duración muy breve. Tan cortos que sólo se reflejan en la amplitud, pero no en el RMS.
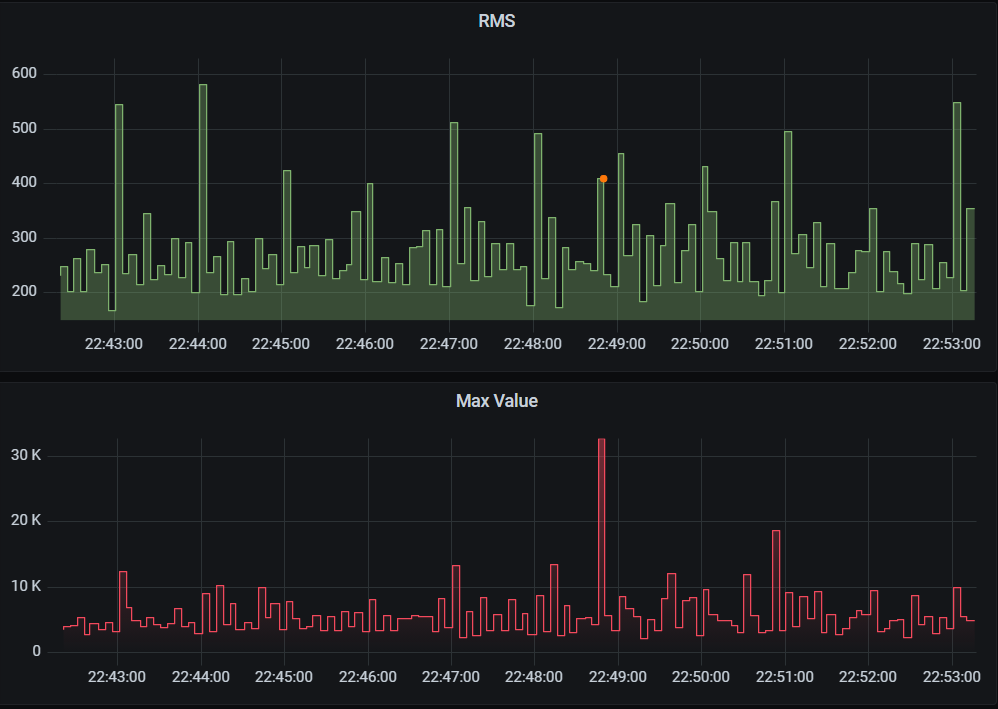
Pico sonoro de duración muy breve. Aumenta la amplitud pero no el RMS. EyC.
También se da el caso contrario: sonidos de poca intensidad, pero duraderos. Un coche pitando en la calle, el despertador del vecino, etc.
Sonido leve pero continuo. Aumenta mucho el RMS, no tanto la amplitud. EyC.
Y, por supuesto, el caso más típico. Un sonido fuerte, perceptible, que aumenta tanto el RMS como la amplitud. Una conversación, un vecino corriendo un mueble, el timbre de la puerta, un golpe, etc.
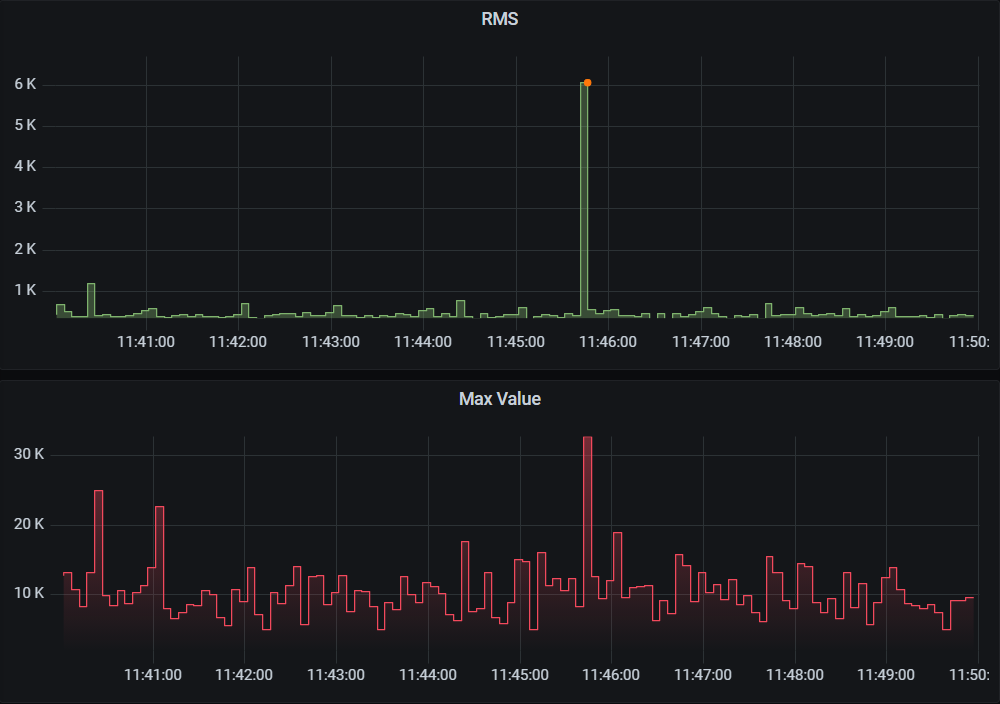
Sonido fuerte. Aumenta el RMS y la amplitud. EyC.
Eventos periódicos
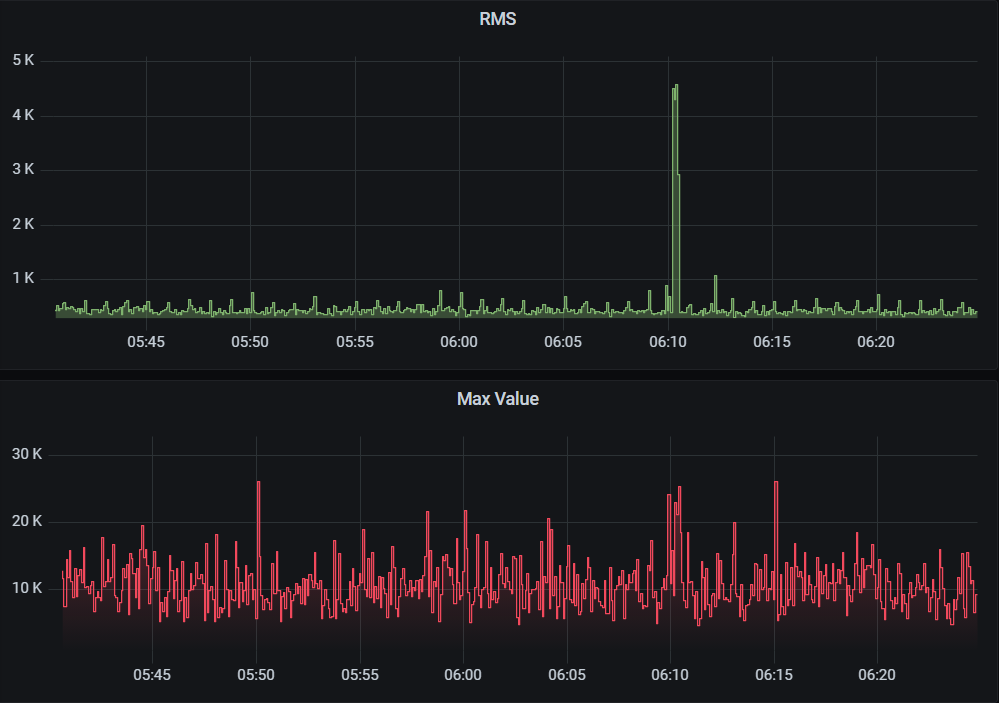
Donde vivo no suele haber ruidos de noche. Observé un pico sobre las 6:00 de la mañana. Es fácil de detectar porque está aislado.
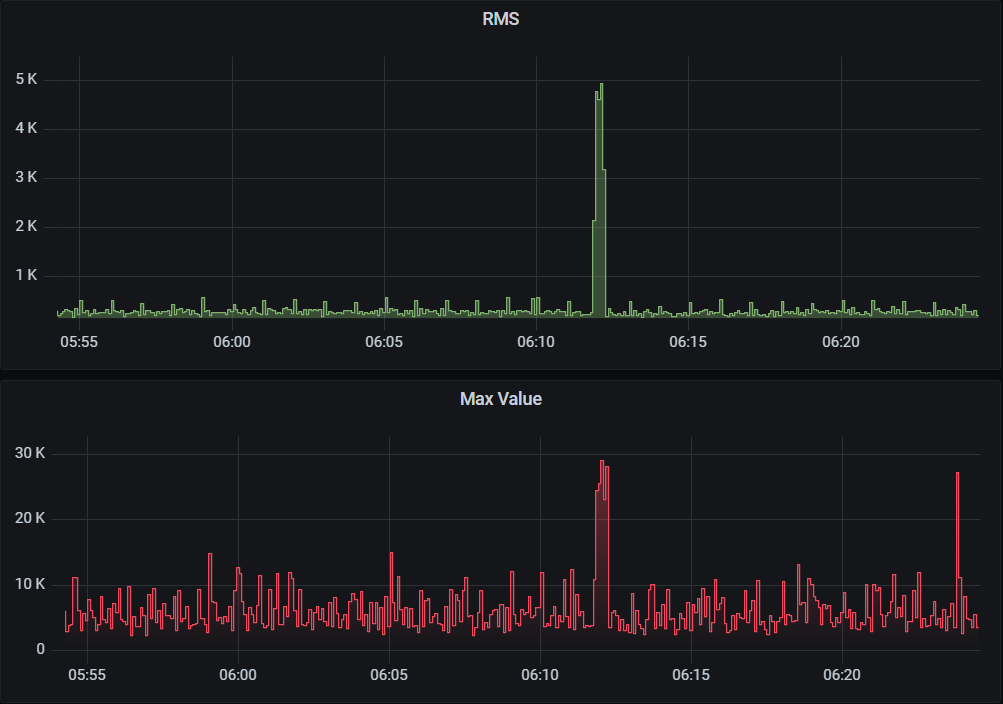
Pico de sonido de madrugada. EyC.
Al día siguiente también. Busqué si ocurría otros días y ahí estaba. ¿Cómo podría encontrar otros eventos periódicos?
Por ejemplo haciendo un panel con los eventos de hoy y los de ayer. Así podremos comparar si hay dos al mismo tiempo. Empiezo por quedarme con los RMS mayores a 2000, eso diremos que es un evento. A la hora de agrupar, lo hacemos con max en lugar de mean. Así resaltarán mejor los picos.
from(bucket: "testing")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "sndobras" and r._field == "rms")
|> aggregateWindow(every: v.windowPeriod, fn: max)
|> filter(fn: (r) => r._value > 2000)
Nos da este panel:
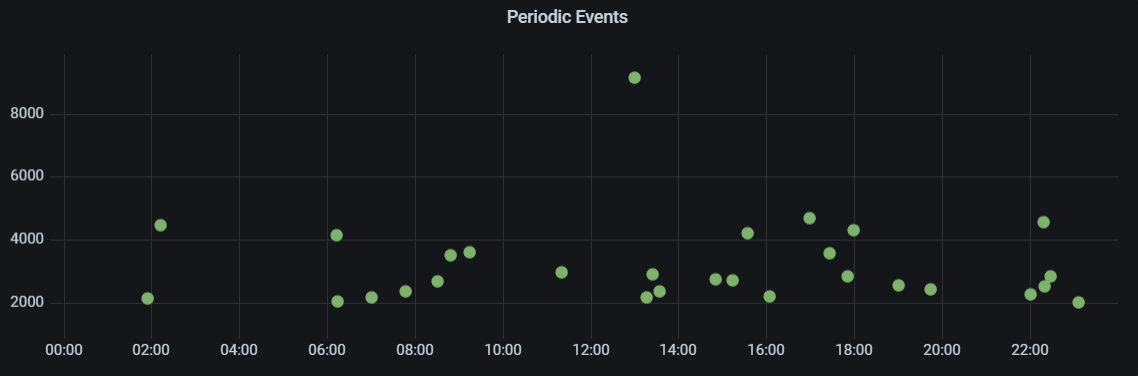
Eventos que superan el umbral de 2000 en RMS en 24h. EyC.
Ahora el mismo intervalo pero de ayer. Añadimos una segunda query modificando los límites de tiempo con subDuration. Además, para hacerlos aparecer sobre los de hoy, desplazo la serie 24h hacia adelante en el tiempo.
import "experimental"
starttime = experimental.subDuration(
d: 1d,
from: v.timeRangeStart
)
stoptime = experimental.subDuration(
d: 1d,
from: v.timeRangeStop
)
from(bucket: "testing")
|> range(start: starttime, stop: stoptime)
|> filter(fn: (r) => r._measurement == "sndobras" and r._field == "rms")
|> aggregateWindow(every: v.windowPeriod, fn: max)
|> filter(fn: (r) => r._value > 2000)
|> timeShift(duration: 1d)
Y obtenemos esto:
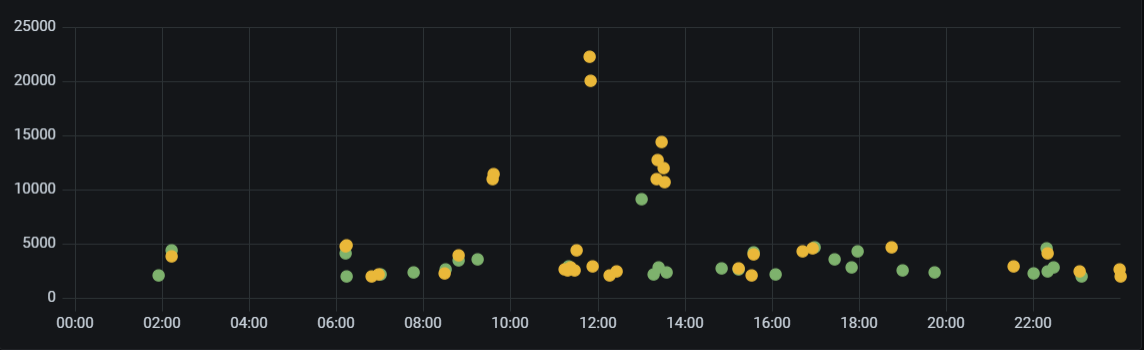
Eventos que superan el umbral de 2000 en RMS en 24h y 48h sobrepuestos. EyC.
Vale, los dos días están superpuestos pero se ve fatal. Ni con otros colores. Pondremos cada día a una altura distinta. Basta sobrescribir los valores de la serie por un un número fijo. Para hoy el 0, ayer el 1, y así. También les cambiaremos el nombre a -1d, -2d, etc..
|> map(fn: (r) => ({ r with _field: "-1d", _value: 1 }))
Ya se distinguen mejor y empiezan a verse algunos patrones:
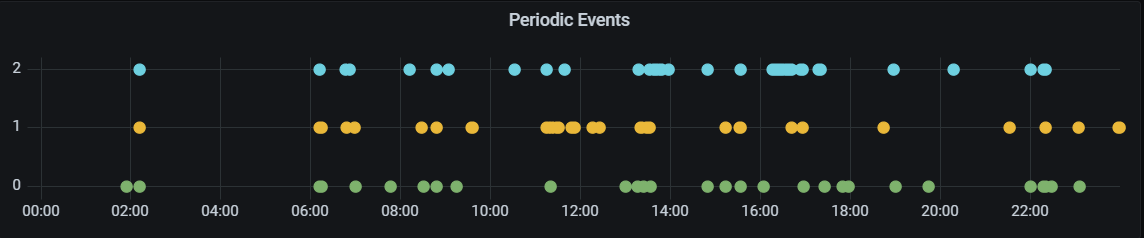
Tres días de eventos a diferentes alturas. EyC.
Ahora sólo queda replicar la query tantas veces como queramos. Este sería el calendario de sonido en una semana.
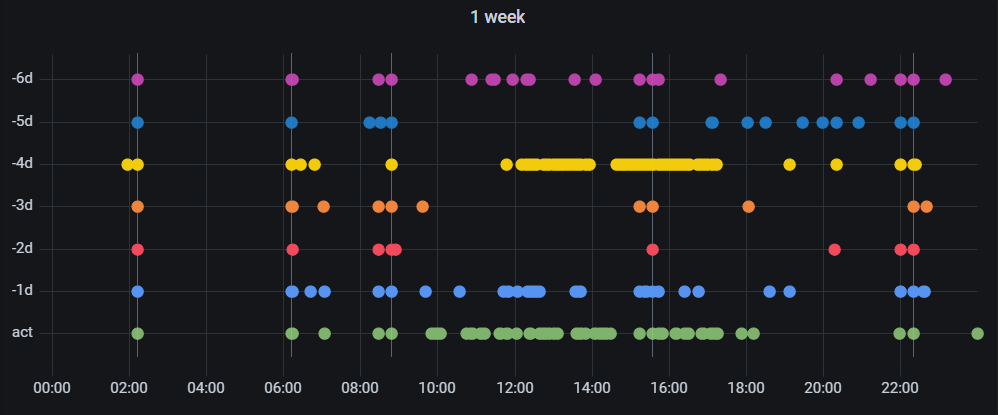
Eventos diarios en una semana. EyC.
Los momentos de más ruido son entre las 10 y las 18. Las tardes y las noches son muy tranquilas.
Hay más eventos periódicos, sin embargo no se trata de algo automático porque no sucede siempre a la misma hora.
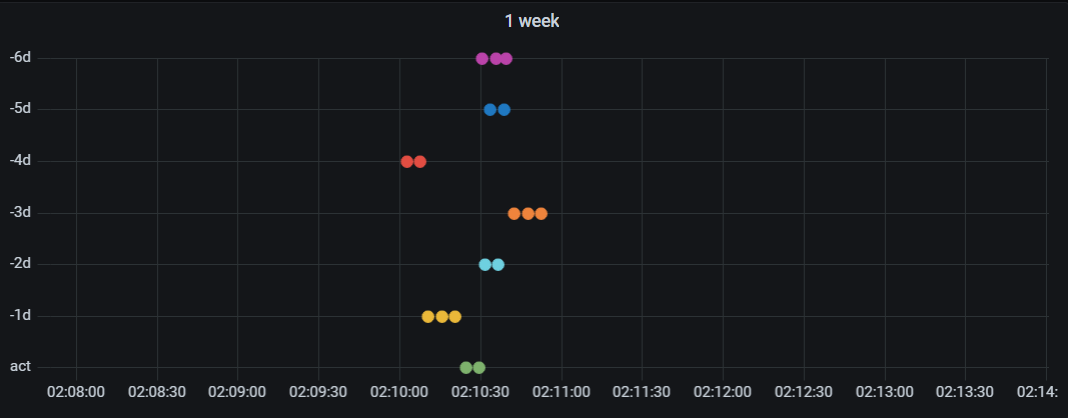
Evento de las 2am. Detalle. EyC.
Conclusión y enlaces
Hemos visto cómo capturar sonido en la Raspberry, filtrarlo con SoX, procesarlo en tiempo real con Python y calcular el RMS. Con un script hemos enviado el resultado al API de InfluxDB Cloud, al mismo tiempo que guardamos el histórico en local. Luego te he descrito varias queries básicas y no tan básicas en Flux. Y, para terminar, hemos diseñado un panel de Grafana con el que identificar fácilmente eventos periódicos.
Repositorio del artículo:
Grafana, InfluxDB y Fluxlang:
- Grafana Cloud
- InfluxDB Cloud
- InfluxDB v2.0 Reference
- Why We’re Building Flux, a New Data Scripting and Query Language
Varios:
Artículos relacionados: