 Electronica y Ciencia
Electronica y CienciaInferencia estadística II: Introducción a los test de hipótesis
En una entrada anterior sobre estadística, nos quedamos a las puertas de hablar de los tests de hipótesis. Los principios de este tema no suelen explicarse del todo bien en los textos de estadística.
Habitualmente se describe lo que son y se presentan varios, cada uno con su estadístico sacado de la nada. Para algunos se despeja la variable y se calcula un valor. Luego se presentan casos de uso y ejemplos prácticos, unas veces a mano y otras con el SPSS o cualquier otro. Después se habla de los errores, etc. No es de extrañar que la profundidad con que se entiende el fondo del asunto dependa mucho del profesor que imparta la asignatura.
En esta entrada continuaré haciéndome preguntas como en la anterior, y los tests de hipótesis más conocidos surgirán de manera natural. Claro está que voy a introducir algunas incorrecciones que me permitan obviar detalles pero esto es un blog, no un curso de estadística.
Recordemos que estábamos estudiando la capacidad de tres cucharas. Estos eran nuestros datos:
Habíamos determinado el intervalo de confianza al 95% de la media para la primera de ellas, que resultó ser entre 3.61ml y 3.85ml. Y nos habíamos hecho preguntas del tipo ¿Entonces la media no es tal o cual? y respondido con unas probabilidades -a menudo bajísimas- de que fuera así. Veamos de donde salen estas probabilidades.
Test t para la media
Decíamos que por el teorema central del límite al tomar medidas de una muestra estas medidas se agrupan en torno al valor de la media de la muestra. El error de esta estimación depende del número de datos y de su varianza. Se la llama Error Cuadrático de la Media (MSE por las siglas en inglés) a esta magnitud:
\[MSE = \frac{\sigma^2}{n}\]Siendo el numerador la varianza (ojo, que \(\sigma^2\) es la varianza, no la varianza al cuadrado. Y el denominador el número de datos de la muestra. Mejor que con el error cuadrático vamos a trabajar con lo que se llama el error estándar, que al igual que la varianza y la desviación estándar no es más que la raíz cuadrada del anterior. Y lo llamaremos SEM -Standar Error of the Mean-. La fórmula queda confusa porque son todo siglas. Pero como del MSE no voy a volver a hablar, podéis olvidarlo.
\[SEM = \sqrt{MSE}\]Y también habíamos dicho que como no sabemos la varianza de la población completa, solo la de nuestra muestra, pues no podemos plantear la normal que deberíamos sino sólo una aproximación llamada distribución t de Student. Sabiendo la media de las medidas que tenemos, y recurriendo a la t de Student habíamos dibujado los intervalos de confianza para la media.
Al igual que en un programa de bricolaje casero (los españoles podéis leerlo con acento vasco si os place), vamos a ver paso a paso cómo hemos hecho el gráfico.
En primer lugar, hemos dibujado una t de Student:
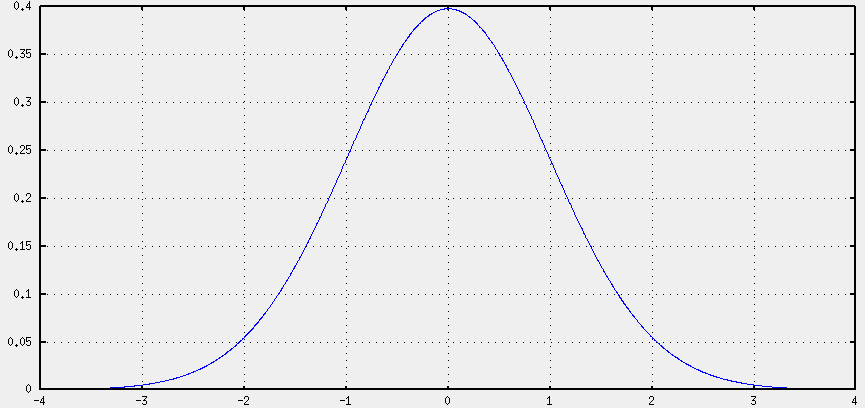
Pero a diferencia de la normal, en la que se indica la media y la varianza, la t sólo depende de un parámetro que es el número de grados de libertad de la muestra. Que para nosotros viene a ser el número de puntos menos uno. Así que habrá que incorporar estos parámetros jugando con el eje X de la gráfica.
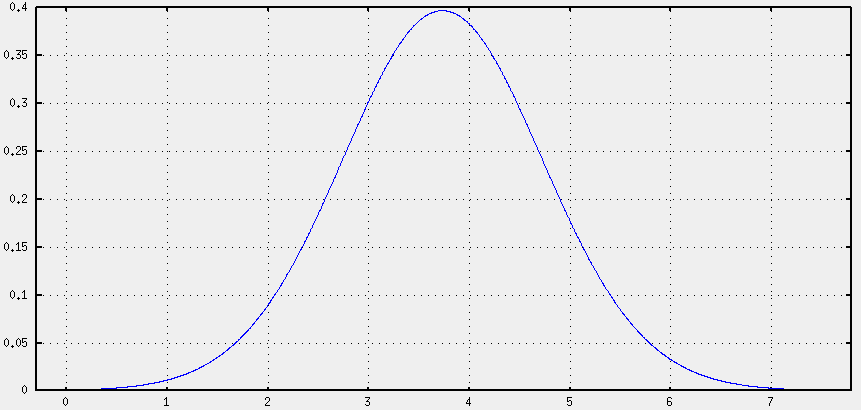
A continuación, hemos desplazado la gráfica. En lugar de graficar tdf(x) hemos graficado tdf(x-media). Así conseguimos que la gráfica que antes estaba centrada en cero, quede centrada en nuestra media. La forma de la gráfica es la misma, sólo cambia el eje X.
Ya sólo nos queda incorporar las unidades al eje X. Ahora mismo está en unidades de error de la media. Para lo cual, procedemos a multiplicar la variable por la unidades que queramos. Como está en errores de la media multiplicaremos por la inversa, o lo que es lo mismo, dividiremos por el error de la media (que habíamos llamado MSE -Mean Squared Error-).
Así pues, en vez de tdf(x-media) graficamos tdf( (x-media)/SEM ).
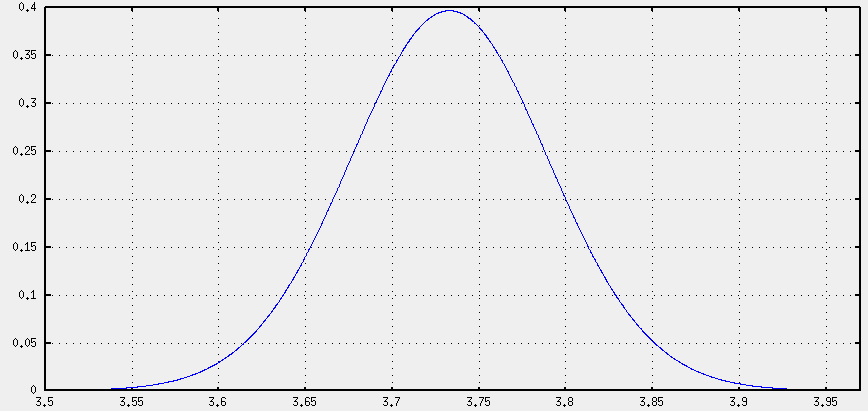
Y es todo, chicos. Con eso ya tenemos nuestra distribución t parametrizada al gusto.
Es fácil darnos cuenta de que la próxima vez que vayamos a calcular algo relativo a la t de Student nos va a ser más útil usar la variable \(\frac{x-media}{SEM}\) que la variable x sola. Pues a
\[t = \frac{x-\mu}{SEM} = \frac{x-\mu}{\sqrt{\sigma^2 \over n}}\]lo llamamos, para variar, el estadístico t de Student. La resta del numerador para unas cosas la veréis así y para otras invertida. Como la distribución es simétrica sólo cambia el signo; si hasta este punto sabéis lo que hacéis no debe importaros mucho.
Ya que tenemos el gráfico, sobre él vamos a responder preguntas. Por ejemplo ¿cuál es la probabilidad de que la media real sea mayor de 3.8? Pues hay que calcular cuánto vale el área sombreada. Que es la integral de la distribución t. Como los programas y las tablas están pensados para la distribución t normalizada, la que hemos visto en el primer gráfico, habrá que utilizar como variable el estadístico t. Como la media era 3.73, teníamos 50 datos y la varianza era 0.168, resulta que el error es SEM=0.058.
Entonces:
\[t = \frac{x-\mu}{SEM} = \frac{3.8 - 3.73}{\sqrt{0.168 \over 50}} = 1.169\]Cualquier programa matemático nos dirá que la integral de toda la distribución que queda a la derecha de 1.169 es 0.124. Eso es equivalente a un 12% de probabilidades de que caiga ahí. La respuesta es 12.4% y se le llama test de hipótesis de una cola.
Si hubiéramos dicho ¿cómo de probable es que esté fuera del intervalo que va de 3.7 a 3.8? Tendríamos que calcular la probabilidad de que sea menor que 3.7 y, por otro lado, la probabilidad de que sea mayor que 3.8 y sumarlas. O bien, calcular la probabilidad de que esté dentro del intervalo, y restarla de 1. Sencillamente porque la probabilidad de que esté en algún sitio es del 100%, o sea 1. Si no está en el intervalo, estará fuera.
La respuesta es 20% y a eso se llama test de dos colas.
Si lo hiciésemos al revés, es decir, “quiero un intervalo tal que la probabilidad de que la media real quede fuera sea de sólo el 5% (0.05) o el 1% (0.01)” ¿qué tendríamos? Pues precisamente un intervalo de confianza para la media.
Comparación de las medias: método básico
La pregunta a la que vamos a responder ahora es: tenemos datos de otras dos cucharas más ¿son distintas entre sí?
Este es el primer método que uno pudiera razonar, pero ya anticipo que no es el que se utiliza porque hay otra forma más fácil de llegar a una conclusión parecida.
De antes sabíamos que el intervalo de confianza al 95% era aquel intervalo en el que podría estar la media; de modo que sólo hay un 5% de probabilidades (según la t de Student) de que las medidas que tenemos pertenezcan a una distribución con una media fuera de ese intervalo. Si no me sigues hasta aquí, será mejor que leas la entrada anterior para refrescarlo.
Ahora bien, si ampliamos los márgenes del intervalo, será más probable que la media esté dentro. En el límite, si el intervalo es todos los números reales la probabilidad de contener la media es 100%, porque ésta es un número real. El problema es que un intervalo que sea toda la recta real no nos aporta información nueva. Que la media era un número, eso ya lo sabíamos. No nos es útil exigir la certeza del 100%.
Sin llegar a ese extremo veamos cómo el intervalo se va ampliando lentamente:
| Al 95% | entre 3.613ml y 3.846ml |
| Al 99% | entre 3.575ml y 3.885ml |
| Al 99.9% | entre 3.527ml y 3.933ml |
| Al 99.999% | entre 3.444ml y 4.016ml |
| Al 99.999999% | entre 3.331ml y 4.129ml |
La cota inferior se va reduciendo y la superior aumenta, por lo que el intervalo, como decíamos, se hace más grande.
Ahora que ya recordamos esto, vamos a calcular la media para la segunda cucharilla. Resulta que la capacidad para esta está entre 3.95 y 4.25ml al 95%. Un criterio para decidir que las medias no coinciden es que los intervalos de confianza no solapen. Mirad esta imagen:
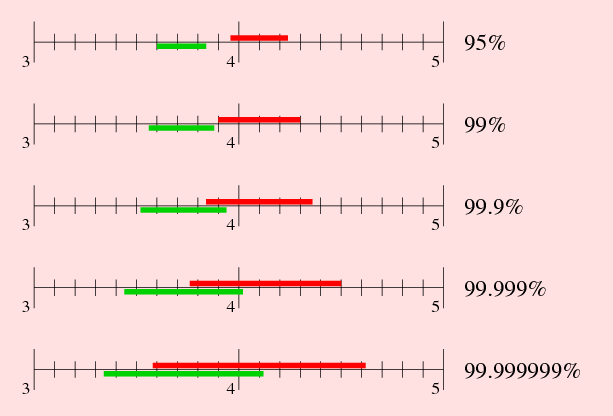
Fijaos en los primeros intervalos, los de 95%. Como el intervalo de primera cucharilla acaba en 3.846 y el de la segunda empieza en 3.951 decidimos que no solapan. Luego las cucharillas tienen distinta capacidad.
Pero claro, a medida que aumentamos la certeza los intervalos se hacen más grandes… hasta que llega un momento que ya sí solapan. Al 99% siguen siendo distintas. Ya no podemos decir lo mismo con una seguridad del 99.9%, porque ahí nuestro criterio ya no se cumple.
No estamos seguros al 99.9% de que las cucharas sean distintas. Para la mayoría de las aplicaciones, el 95% de confianza será suficiente. Dependiendo de para qué necesitamos asegurarlo con el 99%, y también diríamos que son distintas. Si embargo no podemos asegurarlo con una certeza mayor que esa.
Fijaos que en el último intervalo prácticamente se confunden. El rojo crece más rápido porque la varianza de la muestra es más grande que en la otra y por tanto decimos que tiene más error.
Pero la forma de calcularlo como lo hemos hecho ahora tiene algunas desventajas. Y es muy poco formal, no deja de ser una cuenta de la vieja. En las siguientes entradas sobre estadística veremos los dos método más utilizados: el test t para dos muestras y el análisis de la varianza.